

For a bigger project which I hope to blog about soon, I needed to get the OpenCV Java Native Library (JNI) running in a Flink stream. It was a pain in the ass, so I’m putting this here to help the next person.
For OpenCV, you need to statically initialize (I’m probably saying this wrong) the library, so I tried something like this
val stream = env
.addSource(rawVideoConsumer)
.map(record => {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME)
…
Well, that kicks an error that looks like:
Exception in thread "Thread-143" java.lang.UnsatisfiedLinkError: Native Library /usr/lib/jni/libopencv_java330.so already loaded in another classloader
Ok, that’s fair. Multiple task managers, this is getting loaded all over the place. I get it. I tried moving this around a bunch. No luck.
In the Flink-RocksDB connector, and other people have given this advice, the idea is to include the JNI in the resources/fat-jar, then write out a tmp one and have that loaded.
This, for me, resulted in seemingly one tmp copy being generated for each record processed.
import java.io._
/**
* This is an example of an extremely stupid way (and consequently the way Flink does RocksDB) to handle the JNI problem.
*
* DO NOT USE!!
*
* Basically we include libopencv_java330.so in src/main/resources so then it creates a tmp version.
*
* I deleted from it resources, so this would fail. Only try it for academic purposes. E.g. to see what stupid looks like.
*
*/
object NativeUtils {
// heavily based on https://github.com/adamheinrich/native-utils/blob/master/src/main/java/cz/adamh/utils/NativeUtils.java
def loadOpenCVLibFromJar() = {
val temp = File.createTempFile("libopencv_java330", ".so")
temp.deleteOnExit()
val inputStream= getClass().getResourceAsStream("/libopencv_java330.so")
import java.io.FileOutputStream
import java.io.OutputStream
val os = new FileOutputStream(temp)
var readBytes: Int = 0
var buffer = new Array[Byte](1024)
try {
while ({(readBytes = inputStream.read(buffer))
readBytes != -1}) {
os.write(buffer, 0, readBytes)
}
}
finally {
// If read/write fails, close streams safely before throwing an exception
os.close()
inputStream.close
}
System.load(temp.getAbsolutePath)
}
}
There were more accurately like 300 hundred ways I tried to make this S.O.B. work, I’m really just giving you the way points- major strategies I tried in my journey. This is the solution. This is the ‘Tomcat solution’ I’d seen referenced throughout my journey but didn’t understand what they meant. Hence why, I’m writing this blog post.
I created an entirely new module. I called it org.rawkintrevo.cylons.opencv. In that module there is one class.
package org.rawkintrevo.cylon.opencv;
import org.opencv.core.Core;
public class LoadNative {
static {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
}
native void loadNative();
}
I compiled that as a fat jar and dropped it in flink/lib
Then, where I would have run System.loadLibrary(Core.NATIVE_LIBRARY_NAME), I now put Class.forName("org.rawkintrevo.cylon.opencv.LoadNative").
val stream = env
.addSource(rawVideoConsumer)
.map(record => {
// System.loadLibrary(Core.NATIVE_LIBRARY_NAME)
Class.forName("org.rawkintrevo.cylon.opencv.LoadNative")
...
Further, I copy the OpenCV Java wrapper (opencv/build/bin/opencv-330.jar), and library (opencv/build/lib/opencv_java330.so) in flink/lib
Then I have great success and profit.
Good hunting,
tg

Apache Mahout v0.13.0 is out and there are a lot of exciting new features and integration including GPU acceleration, Spark 2.x/Scala 2.10 integration (experimental- full blown in 0.13.1), and a new framework for “precanned algorithms”. In this post we’re going to talk about the new algorithm framework, and how you can contribute to your favorite machine learning on Big Data library.
If you’re not familiar with the Apache Mahout project, it might be helpful to watch this video but in short- it allows you to quickly and easily write your own algorithms in a distributed back-end independent (think Apache Spark, Apache Flink, etc), and mathematically expressive extension of the Scala language. Now v0.13.0 allows the user to accelerate their distribute cluster with GPUs (this is independent of Spark- ANY cluster can be accelerated), and lays out a framework of pre-canned algorithms.
The Algorithms Framework in Apache Mahout, borrows from the traditions of many of the great machine learning and statistical frameworks available today, but most notably- R and Python’s sklearn. When reasonable, Mahout makes a good faith effort to draw on the best parts of each of these.
The first concept we want to address is the idea of a fitter and a model. Now that I have setup the Mahout Algorithms framework, I instantly point out a major break from the way things are done in R and sklearn. As the great thinkers Ralph Waldo Emerson and the person who wrote PEP-8 said, “A foolish consistency is the hobgoblin of little minds.”
In sklearn, the model and the fitter are contained in the same class. In R, there is an implicitly similar paradigm… sometimes.
Model is an object which contains the parameter estimates. The R function lm generates models. In this way, a Fitter in Apache Mahout generates a model of the same name (by convention. E.g. OrdinaryLeastSquares generates an OrdinaryLeastSquaresModel which contains the parameter estimates and a .predict(drmX) method for predicting new values based on the model.
Recap: A Fitter Generates a Model. A model is an object that contains the parameter estimates, fit statistics, summary, and a predict() method.
Now if you’re thinking, “but why?”, good on you for questioning things. Why this break from sklearn? Why not let the fitter and the model live in the same object? The answer is because at the end of the day- we are dealing in big data, and we want our models to be serialized as small as is reasonable. If we were to include everything in the same object (the fitter, with the parameter estimates, etc.) then when we saved the model or shipped it over the network we would have to serialize all of the code required to fit the model and ship that with it. This would be somewhat wasteful.
The following will make the most sense if you understand class hierarchy and class inheritance. If you don’t know/remember these things, now would be a good time to review.

This isn’t a complete diagram but it is illustrative. For example- all Models have a summary string. All SupervisedModels have a Map of testResults. All RegressorModels have a .predict(...) method, and when ClassifierModel is introduced, they may have a .predict(...) method as well, or perhaps they will have a .classify(...) method.
Preprocessors are treated as unsupervised models. They must also be fit. Consider a StandardScaler, which must be “fit” on a data set to learn the mean and standard deviation.
The hierarchy of fitters is identical.
Hyper-parameters are passed in fitter functions as symbols. For example:
val model = new OrdinaryLeastSquares[Int]().fit(drmX, drmY, 'calcCommonStatistics → false)
Different methods have different hyper-parameters which maybe set. This method has advantages of extreme flexibility. It also side-steps the type safety of the Scala language, which depending on weather or not you like or hate type-safety, you might consider to be a good or bad thing. A notable draw back- if you pass a parameter that isn’t used by the method, it will be ignored silently, that is to say it will be ignored and it won’t warn you are throw an error. The real threat here is typos- where you think are doing something like, specifying an interceptless regression, however instead of specifying 'addIntercept -> false you accidentally type 'addInterept -> false, then the regression will add an intercept and throw no warnings that you’ve committed a typo. (This will possibly be fixed soon).
Also, in both hyperparameter examples given have had Boolean values, however the value can be anything. For example, in Cochrane-Orcutt on of the hyperparameters 'regressor can be any sub-class of LinearRegressorFitter!
There are currently three pre-processors available.
* AsFactor which is sometimes referred to as Dummy Variables or One-Hot encoder (Mahout chose R-semantics here over Python)
* StandardScaler which is goes by the same name in sklearn and the function scale in R.
* MeanCenter which is very similar to the standard scaler, however it only centers each column. In the future it is possible that MeanCenter will be combined with StandardScaler (as is done in R).
A fun tip: the unit tests of any package are full of great example. This one comes from: https://github.com/apache/mahout/blob/master/math-scala/src/test/scala/org/apache/mahout/math/algorithms/PreprocessorSuiteBase.scala
val A = drmParallelize(dense( (3, 2, 1, 2), (0, 0, 0, 0), (1, 1, 1, 1)), numPartitions = 2) // 0 -> 2, 3 -> 5, 6 -> 9
AsFactor from Apache Mahoutval factorizer: AsFactorModel = new AsFactor().fit(A) val factoredA = factorizer.transform(A) val myAnswer = factoredA.collect
println(factoredA) println(factorizer.factorMap) val correctAnswer = sparse( svec((3 → 1.0) :: (6 → 1.0) :: (8 → 1.0) :: (11 → 1.0) :: Nil, cardinality = 12), svec((0 → 1.0) :: (4 → 1.0) :: (7 → 1.0) :: ( 9 → 1.0) :: Nil, cardinality = 12), svec((1 → 1.0) :: (5 → 1.0) :: (8 → 1.0) :: (10 → 1.0) :: Nil, cardinality = 12) ) val epsilon = 1E-6 (myAnswer.norm - correctAnswer.norm) should be <= epsilon (myAnswer.norm - correctAnswer.norm) should be <= epsilon
The big call out from the above- is that the interface for this preprocessor (the second block of code) is exceptionally clean for a distributed, GPU accelerated, machine learning package.
There are currently two regressors available:
* OrdinaryLeastSquares – Closed form linear regression
* Cochrane-Orcutt – A method for dealing with Serial Correlation
Oh, horay- another linear regressor for big data. First off- don’t be sassy. Second, OLS in Apache Mahout is closed form- that is to say, it doesn’t rely on Stochastic Gradient Descent to approximate the parameter space β.
Among other things, this means we are able to know the standard errors of our estimates and make a number of statistical inferences, such as the significance of various parameters.
For the initial release of the algorithms framework, OrdinaryLeastSquares was chosen because of its widespread familiarity. CochraneOrcutt was chosen for its relative obscurity (in the Big Data Space). The Cochrane Orcutt procedure is used frequently in econometrics to correct for auto correlation in the error terms. When auto-correlation (sometimes called serial-correlation) is present the standard errors are biased, and so is our statistical inference. The Cochrane Orcutt procedure attempts to correct for this.
It should be noted, implementations of Cochrane-Orcutt in many statistics packages such as R’s orcutt iterate this procedure to convergence. This is ill-advised on small data and big data alike. Kunter et. al recommend no more than three iterations of the Cochrane Orcutt procedure- if suitable parameters are not achieved, the user is advised to use another method to estimate ρ.
The point of implementing the CochraneOrcutt procedure was to show, that the framework is easily extendable to esoteric statistical/machine-learning methods, and users are encouraged to extend and contribute. Observe the implementation of the algorithm, and after groking, the reader will see that the code is quite expressive and tractable, and the majority of the fit method is dedicated to copying variables of interest into the resulting Model object.
val alsmBlaisdellCo = drmParallelize( dense( (20.96, 127.3), (21.40, 130.0), (21.96, 132.7), (21.52, 129.4), (22.39, 135.0), (22.76, 137.1), (23.48, 141.2), (23.66, 142.8), (24.10, 145.5), (24.01, 145.3), (24.54, 148.3), (24.30, 146.4), (25.00, 150.2), (25.64, 153.1), (26.36, 157.3), (26.98, 160.7), (27.52, 164.2), (27.78, 165.6), (28.24, 168.7), (28.78, 171.7) )) val drmY = alsmBlaisdellCo(::, 0 until 1) val drmX = alsmBlaisdellCo(::, 1 until 2)
var coModel = new CochraneOrcutt[Int]().fit(drmX, drmY , ('iterations -> 2))
println(coModel.beta)
println(coModel.se)
println(coModel.rho)
Unlike R and sklearn, all regression statistics should be considered optional, and very few are enabled by default. The rationale for this is that when working on big data, calculating common statistics could be costly enough that, unless the user explicitly wants this information, the calculation should be avoided.
The currently available regression tests are
* CoefficientOfDetermination – calculated by default, also known as the R-Square
* MeanSquareError – calculated by default, aka MSE
* DurbinWatson – not calculated by default, a test for the presence of serial correlation.
When a test is run, the convention is the following:
var model = ... model = new MyTest(model) model.testResults.get(myTest)
The model is then updated with the test result appended to the model’s summary string, and the value of the test result added to the model’s testResults Map.
Apache Mahout’s algorithm framework was designed to be extended. Even with the few example given, it should be evident that it is much more extensible than SparkML/MLLib and even sklearn (as all of the native optimization is abstracted away).
While the user may create their own algorithms with great ease- all are strongly encouraged to contribute back to the project. When creating a “contribution grade” implemenation of an algorithm a few considerations must be taken.
Classifier trait (similar to the Regressor trait).Examples of number three are abound in the current unit tests. Example
Apache Mahout v0.13.0 offers a number of exciting new features, but the algorithms framework is (biasedly) one of my favorite. It is an entire framework that encourages statisticians and data scientists who have until now been intimidated by contributing to open source a green field opportunity to implement their favorite algorithms and commit them to a top-level Apache Software Foundation project.
There has been to date a mutually exclusive choice between ‘powerful, robust, and extendable modeling’ and ‘big data modeling’, each having advantages and disadvantages. It is my sincere hope and believe that the Apache Mahout project will represent the end of that mutual exclusivity.

Apache Mahout has just released the long awaited 0.13.0 which introduces modular native solvers (e.g. GPU support!).
TensorFlow has done a great job driving the conversation around bringing GPU accelerated linear algebra to the masses for implementing custom algorithms, however it has a major draw back that it prefers to manage its own cluster or can work on top of Apache Spark. Mahout on the other hand was designed to work on top of Spark or with any user defined distributed back-end (it just so happens Spark is the generic one we recommend for people trying out Mahout- but if you happen to use Spark great, you’re all set!)
In Mahout, we strive to make everything modular, use something off the shelf or write your own that is optimized to you environment. In 0.13.0 Mahout has introduced a concept of modular native solvers. The native solver is a what gets called when you do any BLAS Like operations (e.g. matrix-matrix multiplication, matrix-vector multiplication, etc.). Many machine learning packages such as R, Python’s sklearn, and Spark’s MLLib utilize Fortran based solvers for speeding up these types of operations. The two native solvers currently included in Mahout are based on ViennaCL, which allow the user to utilize GPUs (via the org.apache.mahout:mahout-native-viennacl_2.10:0.13.0 artifact) or CPUs (via the org.apache.mahout:mahout-native-viennacl-omp_2.10:0.13.0 artifact).
To understand how this gets used in practice, let’s review how Mahout does math on a Distributed Row Matrix (DRM). A DRM is really a wrapper for an underlying data structure, for example in Spark a RDD[org.apache.mahout.math.Vector]. When we do some math in Mahout on a DRM, for example
drmA %*% incoreV
We are taking a DRM (which is wrapping an RDD) and taking the dot product of each row. In Spark for instance, each executor is multiplying every row of each partition it has locally by a vector (taking the dot product), this happens in the JVM.
When a native solver such as ViennaCL is in use, each executor attempts to use the ViennaCL library to dump the data out of the JVM (where the exectutor is running), utilize a GPU if one exists, load the data into the GPU and execute the operation there. (GPUs are super charged for BLAS operations like this).
This works in a similar way using ViennaCL-OMP, the difference is that all available CPUs are used.
Supposing then you have a Spark cluster, and on each node there are GPUs available- then what you now have is statistics/machine learning on Spark which is GPU accelerated. If you have some other distributed engine that executed in the JVM (such as Apache Flink) then you also get GPU acceleration there!
If you don’t have GPUs on your Spark Cluster, you can also use the ViennaCL-OMP package to see significant performance gains. It should be noted though, the optimal ‘tuning’ of one’s Spark jobs changes when using OMP. Since ViennaCL-OMP will utilize all available CPUs, it is advised to set the partitioning of the DRM to be equal to the number of nodes you have. This is because they way Spark normally paralellizes jobs is by using one core per partition to do work- however, since OMP will invoke all cores, you don’t gain anything by ‘over parallelizing’ your job. (This assumes that setting partitions = number of executors will still allow your full data set to fit in memory).
In addition to the super-awesome GPU stuff, there are also a couple of other fun little additions.
Currently this is very sparse, but represents Mahout moving toward offering a large collection of contributed algorithms via a consistent API similar to Python’s sklearn.
Consider classic OLS.
val drmData = drmParallelize(dense( (2, 2, 10.5, 10, 29.509541), // Apple Cinnamon Cheerios (1, 2, 12, 12, 18.042851), // Cap'n'Crunch (1, 1, 12, 13, 22.736446), // Cocoa Puffs (2, 1, 11, 13, 32.207582), // Froot Loops (1, 2, 12, 11, 21.871292), // Honey Graham Ohs (2, 1, 16, 8, 36.187559), // Wheaties Honey Gold (6, 2, 17, 1, 50.764999), // Cheerios (3, 2, 13, 7, 40.400208), // Clusters (3, 3, 13, 4, 45.811716)), numPartitions = 2) val drmX = drmData(::, 0 until 4) val drmY = drmData(::, 4 until 5) import org.apache.mahout.math.algorithms.regression.OrdinaryLeastSquares var model = new OrdinaryLeastSquares[Int]() model.fit(drmX, drmY) model.summary
Which returns:
res3: String = Coef. Estimate Std. Error t-score Pr(Beta=0) X0 -1.336265388326865 2.6878127323908942 -0.49715717625097144 1.354836239139669 X1 -13.157701320678825 5.393984138816236 -2.4393288860442244 1.9287400286811958 X2 -4.152654199019935 1.7849055635870432 -2.326540005105108 1.9194430753543341 X3 -5.67990809423236 1.886871957793384 -3.0102244462177334 1.960458377021527 (Intercept) 163.17932687840948 51.91529676169986 3.143183937239744 0.03474107366050938
Feels just like R, with the one caveat that X0 is not the intercept- a slight cosmetic issue for the time being.
The following algorithms are included as of 0.13.0:
Preprocessing
– AsFactor: Given a column of integers, returns a sparse matrix (also sometimes called “OneHot” encoding).
– MeanCenter: Centers a column on its mean
– StandardScaler: Scales a column to mean= 0 and unit variance.
Regression
– OrdinaryLeastSquares: Closed form ordinary least squares regression
Remedial Measures
– CochraneOrcutt: When serial correlation in the error terms is present the test statistics are biased- this procedure attempts to ‘fix’ the estimates
Tests
– Coefficent of Determination: Also known as R-Squared
– MeanSquareError
– DurbinWatson: Tests for presence of serial correlation
This is a small package that adds Scala-like methods to org.apache.mahout.math.Vector. Specifically it adds the toArray and toMap method.
While these may seem trivial, I for one have found them extremely convenient (which is why I contributed them 🙂 )
Spark can be a really useful tool for getting your data ready for Mahout- however there was a notable lack of methods for easily working with DataFrames or RDDs of org.apache.spark.mllib.linalg.Vector (the kinds of RDD that MLLib likes).
For convenience, the following were added:
–drmWrapMLLibLabledPoint
–drmWrapDataFrame
–drmWrapMLLibVector
drmWrapMLLibLabledPoint
val myRDD: RDD[org.apache.spark.mllib.regression.LabeledPoint] = ... val myDRM = drmWrapMLLibLabeledPoint(myRDD) // myDRM is a DRM where the 'label' is the last column
drmWrapDataFrame
val myRDD: RDD[org.apache.spark.mllib.linalg.Vector] = ... val myDRM = drmWrapMLLibVector(myRDD)
drmWrapMLLibVector
val myDF = ... // a dataframe where all of the values are Doubles val myDRM = drmWrapDataFrame(myDF)
This was a really hard fought release, and an extra special thanks to Andrew Palumbo and Andrew Musselman. If you see them at a bar, buy them a beer; if you see them at a taco stand, buy them some extra guac.
We’re finishing up our series of blogs on providers with YouTube. After this we’ll get down business on building our own social monitoring quasi-app!
Before accessing any API, we of course need to get our credentials.
A good first step in an enterprise like this would be to read the docs, or at least thumb through them, regarding registering an application with the YouTube API.
But if you wanted to read lengthy docs, you probably wouldn’t be checking out this blog- so here’s the short version:
Open the Google Developers Dashboard we’re going to “Create a Project”
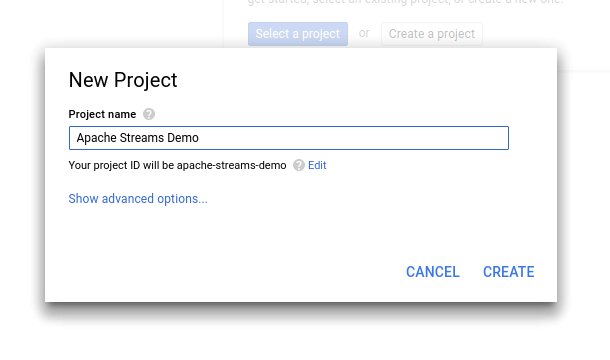
I’m going to call my application “Apache Streams Demo”
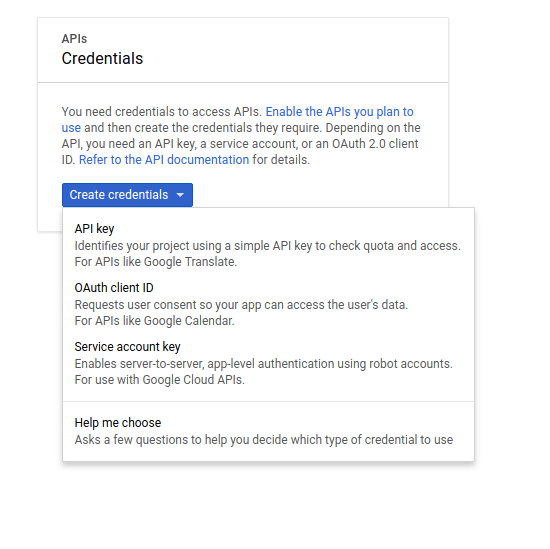
The next dialog is where things can go awry. First, right click “Enable APIs you plan to use” and open that link in a new tab, then click the drop down arrow next to “Create Credentials” and then select “Create Service Account Key” (we’ll come back to API enablement in a minute).
In the next screen choose ‘New Service Account’ and select P12 download type (not JSON which is the default). A dialogue will pop up with some key information. I set permissions to owner, but that probably isn’t necessary. After you hit create the key will be generated and downloaded.
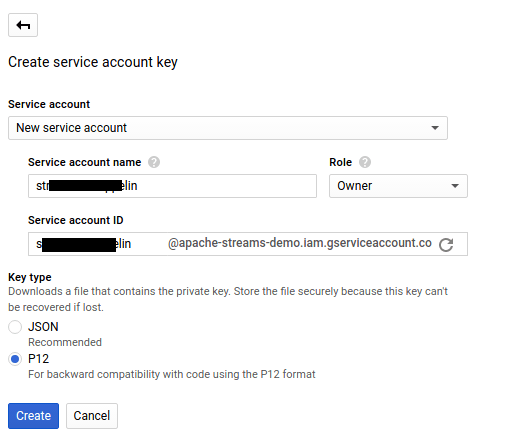
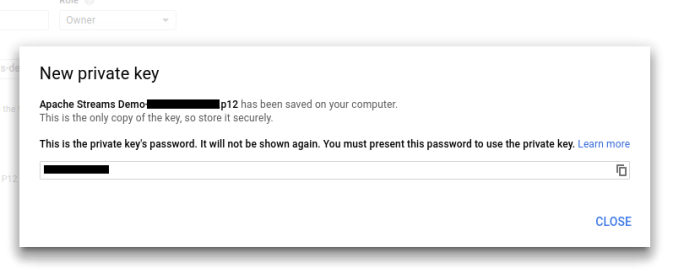
Set that .p12 file aside somewhere safe. We’ll need it soon.
Finally, we need to enable the services we want with this key. Go to the library tab (or open the ‘new tab’ you opened when you were creating the service account.
You’ll see a long list of all the APIs you can grant access to. We want to focus, for the moment on the YouTube services.
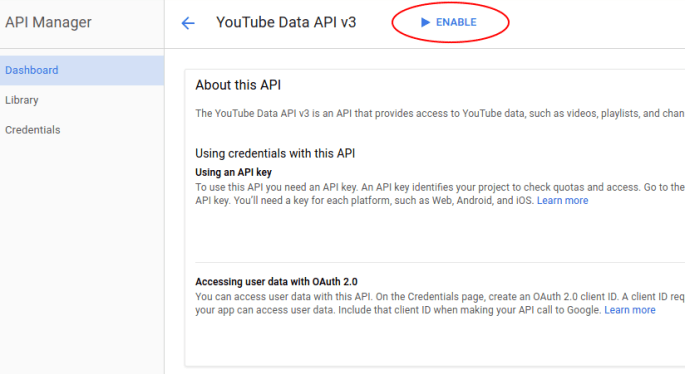
Go through each API you want (the YouTubes for this demo) and click “Enable” at the top.
Full Credit to Steve Blockmon on this well done notebook.
Import Setup.json
Import YouTube.json
Steve and I are working toward a suite of notebooks aimed at creating a Social Monitoring Quasi-App. In the first paragraph of setup.json we see the following paragraph.
%spark.dep
z.reset()
z.addRepo("apache-snapshots").url("https://repository.apache.org/content/repositories/snapshots").snapshot()
z.load("org.apache.streams:streams-core:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-converters:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-pojo:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-provider-twitter:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-provider-facebook:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-provider-youtube:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:google-gplus:0.5-incubating-SNAPSHOT")
We’re using the Zeppelin Dependency Loader here (you’ll likely see a message how this is deprecated). At the time of writing, there seems to be an issue with adding repositories via the GUI (e.g. it doesn’t pick up the new repository URL).
z.addRepo(... does add the new repository- in this case the Apache SNAPSHOT repository. The remaining lines load various Apache Streams providers.
In the next paragraph of the notebook Steve defines a couple of UDFs for dealing with punctuation and spaces in tweets and descriptions. These will come in handy later and are worth taking a moment to briefly grok.
The first paragraph isn’t too exciting- some simple imports:
%spark import org.apache.streams.config._ import org.apache.streams.core._ import org.apache.youtube.pojo._ import com.typesafe.config._ import com.youtube.provider._ import java.util.Iterator
The second paragraph is where things start to get interesting. As we do, we are building a hocon configuration. We are also leveraging Zeppelin Dynamic Forms
val apiKey = z.input("apiKey", "")
val serviceAccountEmailAddress = z.input("serviceAccountEmailAddress", "")
val pathToP12KeyFile = z.input("pathToP12KeyFile", "")
val credentials_hocon = s"""
youtube {
apiKey = $apiKey
oauth {
serviceAccountEmailAddress = "$serviceAccountEmailAddress"
pathToP12KeyFile = "$pathToP12KeyFile"
}
}
"""
This paragraph will yield:

To find your API Key and Service account (assuming you didn’t write them down earlier- tsk tsk). Go back to your Google Developers Console, on the Credentials Tab, and click “manage service accounts” on the right. On this page you will see your service account and API Key. If you have multiple- make sure to use the one that cooresponds to the .p12 file you downloaded.

After you enter your crendentials and path to .p12file- make sure to click the “Play” button again to re-run the paragraph and update with your credentials.
The next configuration specifies who we want to follow. It is a list of UserIDs.
%spark
val accounts_hocon = s"""
youtube.youtubeUsers = [
# Apache Software Foundation - Topic
{ userId = "UCegQNPmRCAJvCq6JfHUKZ9A"},
# Apache Software Foundation
{ userId = "TheApacheFoundation"},
# Apache Spark
{ userId = "TheApacheSpark" },
# Apache Spark - Topic
{ userId = "UCwhtqOdWyCuqOboj-E1bpFQ"},
# Apache Flink Berlin
{ userId = "UCY8_lgiZLZErZPF47a2hXMA"},
# Apache Syncope
{ userId = "UCkrSQVb5Qzb13crS1kCOiQQ"},
# Apache Accumulo
{ userId = "apacheaccumulo"},
# Apache Hive - Topic
{ userId = "UCIjbkZAX5VlvSKoSzNUHIoQ"},
# Apache HBase - Topic
{ userId = "UCcGNHRiO9bi6BeH5OdhY2Kw"},
# Apache Cassandra - Topic
{ userId = "UC6nsS04n_wBpCDXqSAkFM-w"},
# Apache Hadoop - Topic
{ userId = "UCgRu3LbCjczooTVI9VSvstg"},
# Apache Avro - Topic
{ userId = "UCzHCk8Gl5eP85xz0HwXjkzw"},
# Apache Maven - Topic
{ userId = "UCBS2s2cwx-MW9rVeKwee_VA"},
# Apache Oozie - Topic
{ userId = "UCRyBrviuu3qMNliolYXvC0g"},
]
"""
I would recommend you stick with this list if you don’t have any activity on YouTube, or you’re just getting started and want to make sure some data is coming in. But in the spirit of creating our own little social monitoring quasi-app, consider replacing the proceeding paragraph with this:
%spark
val myChannel = z.input("my YouTube Channel", "")
val myId = z.input("my ID", "")
val accounts_hocon = s"""
youtube.youtubeUsers = [
{ userId = "${myId}"},
{ userId = "${myChannel}"}
]
"""
Which is going to give you a dynamic form in which a user can insert their own YouTube channel Id.
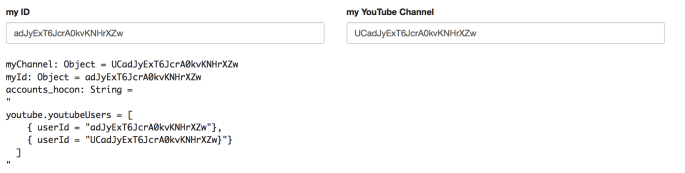
You’ll note here I have put in both my User ID and channel Id, and the only difference is adJyExT6JcrA0kvKNHrXZw vs UCadJyExT6JcrA0kvKNHrXZw is the proceeding UC in the latter- denoting it is a channel. Further if you notice the code- you submit User ID and channel ID as userId=.... This may be helpful because as we will see the channel and user APIs give us slightly different information.
To find channel IDs just surf around YouTube and go to channel pages. You’ll see the address is something like https://www.youtube.com/channel/UCGsMOj1pUwabpurXSKzfIfg (which is Astronomia Nova) and the UCGsMOj1pUwabpurXSKzfIfg part is the user ID.
First we’re going to set up a ConfigFactory to load our config strings which we just did. This is going to create our YouTube configuration.
%spark val reference = ConfigFactory.load() val credentials = ConfigFactory.parseString(credentials_hocon) val accounts = ConfigFactory.parseString(accounts_hocon) val typesafe = accounts.withFallback(credentials).withFallback(reference).resolve() val youtubeConfiguration = new ComponentConfigurator(classOf[YoutubeConfiguration]).detectConfiguration(typesafe, "youtube");
Next we will pull information about the Channel(s) we noted in our accounts_hocon config string. This may be all of the Apache Accounts or our personal one. We will create an ArrayBuffer to store all of the responses we get. This should be old hat by now- you’ll notice the very similar API as accessing the Facebook and Twitter APIs from previous posts.
%spark
import com.typesafe.config._
import org.apache.streams.config._
import org.apache.streams.core._
import com.youtube.provider._
import org.apache.youtube.pojo._
import java.util.Iterator
val youtubeChannelProvider = new YoutubeChannelProvider(youtubeConfiguration);
youtubeChannelProvider.prepare(null)
youtubeChannelProvider.startStream()
val channel_buf = scala.collection.mutable.ArrayBuffer.empty[Object]
while( youtubeChannelProvider.isRunning()) {
val resultSet = youtubeChannelProvider.readCurrent()
resultSet.size()
val iterator = resultSet.iterator();
while(iterator.hasNext()) {
val datum = iterator.next();
channel_buf += datum.getDocument
}
}
channel_buf.size
The important thing to watch for, especially if using something other than the Apache userID set is that the output of the previous paragraph doesn’t end with something like: res45: Int = 0 because if that is the case- your buffer is empty and you will get errors when you try to make a table. If your buffer is empty, try using different user Ids.
Next we’ll get the user activity results.
%spark
val buf = scala.collection.mutable.ArrayBuffer.empty[Object]
val provider = new YoutubeUserActivityProvider(youtubeConfiguration);
provider.prepare(null)
provider.startStream()
while(provider.isRunning()) {
val resultSet = provider.readCurrent()
resultSet.size()
val iterator = resultSet.iterator();
while(iterator.hasNext()) {
val datum = iterator.next();
//println(datum.getDocument)
buf += datum.getDocument
}
}
buf.size
Basically the same idea here- same as last time, make sure that buffer is greater than 0!
Our goal here is to get our data into a format we can play with. The easiest route to this end is to leverage Spark DataFrames / SQL Context and Zeppelin’s table display.
At the end of the last session on Apache Streams, we left as an exercise to the user a way to untangle all of the messy characters and line feeds. Now we provide the solution, a couple of User Defined Functions (UDFs) to strip all of that bad noise out.
%spark
import org.apache.spark.sql.functions._
import org.apache.spark.sql.UserDefinedFunction
import java.util.regex.Pattern
val toLowerCase = udf {
(text: String) => text.toLowerCase
}
val removeLineBreaks = udf {
(text: String) =>
val regex = "[\\n\\r]"
val pattern = Pattern.compile(regex)
val matcher = pattern.matcher(text)
// Remove all matches, split at whitespace (repeated whitespace is allowed) then join again.
val cleanedText = matcher.replaceAll(" ").split("[ ]+").mkString(" ")
cleanedText
}
val removePunctuationAndSpecialChar = udf {
(text: String) =>
val regex = "[\\.\\,\\:\\-\\!\\?\\n\\t,\\%\\#\\*\\|\\=\\(\\)\\\"\\>\\ posts(s)
val YoutubeTypeConverter = new YoutubeTypeConverter()
YoutubeTypeConverter.prepare()
val pages_datums = channel_buf.flatMap(x => YoutubeTypeConverter.process(new StreamsDatum(x)))
Now we create our DataFrame and register it as a temp table. Notice we use our “cleaner function” aka removePunctuationAndSpecialChar to clean column summary. This gives us a nice clean summary, while preserving the original actor.summary. If actor.summary doesn’t make any sense as a column name, see when we get to querying the table- it has to do with how spark queries the nested fields of a JSON.
%spark
import org.apache.streams.jackson.StreamsJacksonMapper;
import sqlContext._
import sqlContext.implicits._
val mapper = StreamsJacksonMapper.getInstance();
val pages_jsons = pages_datums.map(o => mapper.writeValueAsString(o.getDocument))
val pagesRDD = sc.parallelize(pages_jsons)
val pagesDF = sqlContext.read.json(pagesRDD)
val cleanDF = pagesDF.withColumn("summary", removePunctuationAndSpecialChar(pagesDF("actor.summary")))
cleanDF.registerTempTable("youtube_pages")
cleanDF.printSchema
In the line where we create page_json we do a map over the pages_datums we had created just previously (which was type scala.collection.mutable.ArrayBuffer[org.apache.streams.core.StreamsDatum] if you’re in to that sort of thing), changing each StreamsDatum into a JSON. We then paralellize that array, and do the standard Spark things to create a DataFrame from the RDD. Hocus-pocus and our channels have now been processed into a temp table called youtube_pages. The process is repeated for our users’ posts.
%spark import org.apache.streams.core.StreamsDatum import com.youtube.processor._ import scala.collection.JavaConversions._ //Normalize activities -> posts(s) val YoutubeTypeConverter = new YoutubeTypeConverter() YoutubeTypeConverter.prepare() val useractivity_posts = buf.flatMap(x => YoutubeTypeConverter.process(new StreamsDatum(x)))
And then…
%spark
import org.apache.streams.jackson.StreamsJacksonMapper;
import sqlContext._
import sqlContext.implicits._
val mapper = StreamsJacksonMapper.getInstance();
val jsons = useractivity_posts.map(o => mapper.writeValueAsString(o.getDocument))
val activitiesRDD = sc.parallelize(jsons)
val activitiesDF = sqlContext.read.json(activitiesRDD)
val cleanDF = activitiesDF.withColumn("content", removePunctuationAndSpecialChar(activitiesDF("content")))
cleanDF.registerTempTable("youtube_posts")
cleanDF.printSchema
Same idea, now we have a table called youtube_posts.
At the end of the second paragraph for pages and posts above we called the .printSchema method on our DataFrame. This is helpful because it shows us … the schema of the DataFrame, which in a non-flat format such as JSON can be very useful. In general to traverse this schema we use field.subfield.subsubfield to query these things. Consider the following SQL statment:
%spark.sql select actor.id , actor.displayName , summary , actor.extensions.followers , actor.extensions.posts , extensions.youtube.statistics.viewCount from youtube_pages
and
%spark.sql select id , published , actor.id , actor.displayName , content , title from youtube_posts
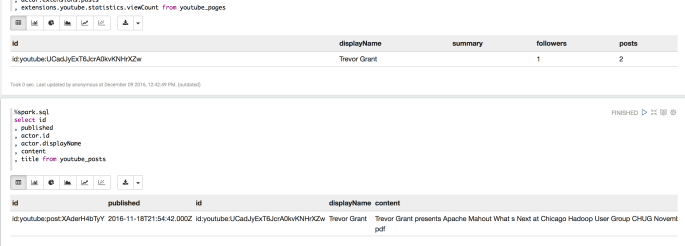
Here we see, I’m not such a popular guy on YouTube; 1 follower, 23 views, 1 post (a recent Apache Mahout Talk). My chance at being one of the great YouTube bloggers has passed me by, such is life.
The story arch of this series on Apache Streams has reached its zenith. If you have been following along, you’ll notice there isn’t really so much new information per Apache Streams anymore- the posts are more dedicated to ‘How to get your credentials for provider X’. I was thinking about doing one last one on Google+ since the credentialing is essentially the same, and you only need to change a couple of lines of code to say Google instead of YouTube.
In the dramatic conclusion to the Apache Streams mini-saga, we’re going to combine all of these together into a ‘quasi-app’ in which you collect all of your data from various providers and start merging it together using Spark SQL, visualizing with Angular, Zeppelin, and D3Js, and a little machine learning to see if we can’t learn a little something about our selves and the social world/bubble we (personally) live in.

This week we’re going to really show off how easy it is to “roll our own” algorithms in Apache Mahout by looking at Eigenfaces. This algorithm is really easy and fun in Mahout because Mahout comes with a first class distributed stochastic singular value decomposition Mahout SSVD.
This is going to be a big job, and assumes you are have HDFS, and a small cluster to work with. You may be able to run this on your laptop, but I would recommend following the last post on setting up a small cloud-based hadoop cluster with Apache Zeppelin.
Eigenfaces are an image equivelent(ish) to eigenvectors if you recall your high school linear algebra classes. If you don’t recall: read wikipedia otherwise, it is a set of ‘faces’ that by a linear combination can be used to represent other faces.
The first thing we’re going to do is collect a set of 13,232 face images (250×250 pixels) from the Labeled Faces in the Wild data set.
Because some of these shell commands take a little while to run, it is worth taking a moment to set shell.command.timeout.millisecs in the sh interpreter to 600000.
My first paragraph, I’m going to make a directory for my final eigenface images that Zeppelin’s HTML loader can use. Then I’m going to download and untar the dataset. Finally, I’ll put the dataset into the tmp folder in HDFS.
%sh mkdir zeppelin-0.7.0-SNAPSHOT/webapps/webapp/eigenfaces wget http://vis-www.cs.umass.edu/lfw/lfw-deepfunneled.tgz tar -xzf lfw-deepfunneled.tgz hdfs dfs -put /home/guest/lfw-deepfunneled /tmp/lfw-deepfunneled
We use the Scala package scrimage to do our image processing, so we’ll want to add those jars. Also, there is a bug we’re working on in Mahout where broadcasting vectors doesn’t work so well in shell / Zeppelin mode. To get around this, I have added the transformer I need in custom jar of algorithms I use.
MAHOUT-1892: Broadcasting Vectors in Mahout-Shell
If that issue is still open, you’ll need to clone and build my branch (or make your own jar).
git clone https://github.com/rawkintrevo/mahout cd mahout git checkout mahout-1856 mvn clean package -DskipTests
Finally, assuming you are using Big Insights on Hadoop Cloud, you’ll need to copy the jar to the cluster.
scp algos/target/mahout-algos_2.10-0.12.3-SNAPSHOT.jar username@bi-hadoop-prod-XXX.bi.services.us-south.bluemix.net:/home/guest/mahout-algos_2.10-0.12.3-SNAPSHOT.jar
Changing username to your username and bi-hadoop-prod-XXX.bi.services.us-south.bluemix.net to your server address.
Back in Zeppelin, load the dependencies:
%sparkMahout.dep
z.load("com.sksamuel.scrimage:scrimage-core_2.10:2.1.0")
z.load("com.sksamuel.scrimage:scrimage-io-extra_2.10:2.1.0")
z.load("com.sksamuel.scrimage:scrimage-filters_2.10:2.1.0")
// add EXPERIMENTAL mahout algos
// https://github.com/rawkintrevo/mahout/tree/mahout-1856/algos
z.load("/home/guest/mahout-algos_2.10-0.12.3-SNAPSHOT.jar")
This step imports the Mahout packages and sets up the Mahout Distributed Context
%sparkMahout.spark import org.apache.mahout.math._ import org.apache.mahout.math.scalabindings._ import org.apache.mahout.math.drm._ import org.apache.mahout.math.scalabindings.RLikeOps._ import org.apache.mahout.math.drm.RLikeDrmOps._ import org.apache.mahout.sparkbindings._ @transient implicit val sdc: org.apache.mahout.sparkbindings.SparkDistributedContext = sc2sdc(sc)
When doing image processing, we want a Matrix where each image is represented as a vector of numbers, where the number correspond to each pixel.
%sparkMahout.spark
import com.sksamuel.scrimage._
import com.sksamuel.scrimage.filter.GrayscaleFilter
val imagesRDD:DrmRdd[Int] = sc.binaryFiles("/tmp/lfw-deepfunneled/*/*", 500)
.map(o => new DenseVector( Image.apply(o._2.toArray)
.filter(GrayscaleFilter)
.pixels
.map(p => p.toInt.toDouble / 10000000)) )
.zipWithIndex
.map(o => (o._2.toInt, o._1))
val imagesDRM = drmWrap(rdd= imagesRDD).par(min = 500).checkpoint()
println(s"Dataset: ${imagesDRM.nrow} images, ${imagesDRM.ncol} pixels per image")
sc.binaryFiles is the spark way to read in our images. We set out partitioning to 500, and map each image into a scrimage object which drops the color information (we don’t need it for feature mapping) and converts the image to an array of large integers. We scale the integers down, and use the array to create a Mahout DenseVector. Finally we zipWithIndex and then use drmWrap to transform our RDD into a DRM.
IF vector broadcasting in the shell were working (it may be by the time you read this), this is how we would subtract our means.
%sparkMahout.spark
// How you would do this without help
// Doesn't work re BUG: MAHOUT-1892
val colMeansV = imagesDRM.colMeans
val bcastV = drmBroadcast(colMeansV)
val smImages = input.mapBlock(imagesDRM.ncol) {
case (keys, block) =>
val copy: Matrix = block.cloned
copy.foreach(row => row -= bcastV.value)
(keys, copy)
}
We use the .colMeans method to get the colmeans, and then do a mapBlock on the images matrix, subtracting the mean from each image.
Since at the moment the above does not work, here is the hack to do it.
%sparkMahout.spark // EXPERIMENTAL https://github.com/apache/mahout/pull/246 import org.apache.mahout.algos.transformer.SubtractMean // Subtract Mean transforms each row by subtracting the column mean val smTransformer = new SubtractMean() smTransformer.fit(imagesDRM) // calculuates the column mean val smImages = smTransformer.transform(imagesDRM) // return new DRM of subtracted means smImages.checkpoint()
Again, this is only needed as a work around. If you’re interested in how easy it is to package your own functions into a jar- check out the SubtractMean source code
Based primarily on Nathan Halko’s dissertation most of the hard part here is done for us.
%sparkMahout.spark import org.apache.mahout.math._ import decompositions._ import drm._ val(drmU, drmV, s) = dssvd(smImages, k= 20, p= 15, q = 0)
Here k is rank of the output e.g. the number of eigenfaces we want out. p is oversampling parameter, and q is the number of additional power iterations. Read Nathan’s paper or see ssvd docs for more information.
The above will take some time- about 35 minutes on a 5-node Big Insights Cloud Cluster.
drmV will be contain our Eigenfaces (transposed).
drmU will tell us the composition of each face we fed into the algorithm. For example
%sparkMahout drmU.collect(0 until 1, ::)
yields
{0:-5.728272924185402E-4,1:0.005311020699576641,2:-0.009218182156949998,3:0.008125182744744356,4:0.001847134204087927,5:-0.01391318137456792,6:0.0038760898878500913,7:0.0022845256274037842,8:0.007046521884887152,9:0.004835772814429175,10:0.00338488781174816,11:0.009318311263249005,12:-0.005181665861179919,13:-0.004665157429436422,14:0.003072181956470255,15:-0.01285733757511248,16:0.005066140593688097,17:-0.016895601017982726,18:-0.012156252679821318,19:-0.008044144986630029 ... }
Which implies the first image = .005 * eigenFace1 + -.009 * eigenFace2 + …
We want to SEE our eigenfaces! We use scrimage again to help us reconstruct our calculated eigenfaces back in to images.
%sparkMahout.spark
import java.io.File
import javax.imageio.ImageIO
val sampleImagePath = "/home/guest/lfw-deepfunneled/Aaron_Eckhart/Aaron_Eckhart_0001.jpg"
val sampleImage = ImageIO.read(new File(sampleImagePath))
val w = sampleImage.getWidth
val h = sampleImage.getHeight
val eigenFaces = drmV.t.collect(::,::)
val colMeans = smImages.colMeans
for (i <- 0 until 20){
val v = (eigenFaces(i, ::) + colMeans) * 10000000
val output = new Array[com.sksamuel.scrimage.Pixel](v.size)
for (i <- 0 until v.size) {
output(i) = Pixel(v.get(i).toInt)
}
val image = Image(w, h, output)
image.output(new File(s"/home/guest/zeppelin-0.7.0-SNAPSHOT/webapps/webapp/eigenfaces/${i}.png"))
}
First we load a sampleImage so we can get the height and width. I could have just opened it up in an Image viewer, but y’know, code. drmV has our eigenfaces as columns, so we transpose that. Also recall we subtracted the column means when we in-processed the images, so we’ll need to add that back.
We do a simple for loop over the eigenFaces, basically undoing the inprocessing we did. We then create an array of pixels, we do that by iterating through the vector. Finally we create the image with the width and height, and save it to the directory we set up. ZEPPELIN_HOME/webapps/webapp/ is the root directory for the %html interpreter, so we save our images in a directory there (we created this directory at the beginning).
Scala is fun, but for simple string and list manipulation, I love Python
%python r = 4 c = 5 print '%html\n<table style="width:100%">' + "".join(["<tr>" + "".join([ '<td><img src="eigenfaces/%i.png"></td>' % (i + j) for j in range(0, c) ]) + "</tr>" for i in range(0, r * c, r +1 ) ]) + '</table>'
All that does is create an html table of our images.
And that’s it!
I hope you enjoyed this one as much as I did, please leave comments and let me know how it went for you.

In out last adventure we got did a basic example of Apache Streams with Twitter data. This week we’re going to extend that example with Facebook data! Also note, if this seems a little light it is because it’s not that different from the last post and the full explanations are there. Our goal here is not to explain all of Apache Streams (last week) but to begin branching out into other providers.
The first step in any new provider is going to be to go get credentials. To get Facebook credentials you’ll need to visit Facebook App Dashboard. Once you get there and sign up, you’ll need to click “Add new App” (top right). After you’ve create the new app click “Settings”, in the panel to right. Here you will see the “AppID”, and if you click “Click show to see App Secret”, you’ll have two important strings you’re going to need soon.
The final piece of credentials you’ll need to set up is a userAccessToken. The easiest way to do this is to go to Graph API Explorer. These are temporary tokens that expire quickly (after an hour or so). This isn’t a “production” grade approach, but it is a good way to test things out and get going. Persistent tokening with Facebook is out of scope of this blog post and things which I care about at this point in my life.
First you’ll need to add some dependencies, including the Facebook provider jar:
%spark.dep
z.reset()
z.addRepo("apache-snapshots").url("https://repository.apache.org/content/repositories/snapshots").snapshot()
z.load("org.apache.streams:streams-provider-facebook:0.4-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-converters:0.4-incubating-SNAPSHOT")
Next we create a paragraph to make a cute little GUI for entering our credentials.
%spark.spark
val appId = z.input("appId", "")
val appSecret = z.input("appSecret", "")
val userAccessToken = z.input("userAccessToken", "")
That’s going to create a from where you (or your friends) can copy paste their credentials into.

You’ll also want all of your inputs… and there are a LOT. (Likely not all necessary).
%spark.spark import com.typesafe.config._ import org.apache.streams.config._ import org.apache.streams.converter.ActivityConverterProcessor import org.apache.streams.core.StreamsProcessor import org.apache.streams.core._ import org.apache.streams.facebook._ import org.apache.streams.facebook.FacebookUserInformationConfiguration import org.apache.streams.facebook.FacebookUserstreamConfiguration import org.apache.streams.facebook.Page import org.apache.streams.facebook.Post import org.apache.streams.facebook.processor.FacebookTypeConverter import org.apache.streams.facebook.provider.FacebookFriendFeedProvider import org.apache.streams.jackson.StreamsJacksonMapper; import org.apache.streams.pojo.json.Activity import scala.collection.JavaConverters import scala.collection.JavaConversions._ import java.util.Iterator
Next we’ll create the config files. We dynamically create this string based on the values we enter at our little GUI we made. The info section is supposed list which users your are interested in. I think for this provider it is not important especially considering the way we got our AccessToken. In this case it basically just gives you everything you are entitled to and nothing else. Specifically this provider gives you a stream of everything your friends are doing.
%spark
val credentials =
s"""
{
facebook {
oauth {
appId = "$appId"
appSecret = $appSecret
userAccessToken = $userAccessToken
}
info = [
rawkintrevo
]
}
}
"""
val credentialsConfig = ConfigFactory.parseString(credentials)
val typesafe = ConfigFactory.parseString(credentials)
val config = new ComponentConfigurator(classOf[FacebookUserstreamConfiguration]).detectConfiguration(typesafe, "facebook");
val provider = new FacebookFriendFeedProvider(config, classOf[org.apache.streams.facebook.Post] );
val timeline_buf = scala.collection.mutable.ArrayBuffer.empty[Object]
provider.prepare()
provider.startStream()
This should look very similar to the setup we did for the Twitter stream, except of course we are using FacebookUserstreamConfiguration and the FacebookFriendFeedProvider classes, and our stream will consist of org.apache.streams.facebook.Posts
%spark
//while(provider.isRunning()) {
for (i <- 0 to 20) {
val resultSet = provider.readCurrent()
resultSet.size()
val iterator = resultSet.iterator();
while(iterator.hasNext()) {
val datum = iterator.next();
//println(datum.getDocument)
timeline_buf += datum.getDocument
}
println(s"Iteration $i")
}
provider.cleanUp()
The key difference here is that we stop running after 40 iterations. That should be PLENTY of data. If we use the while loop, this would run forever updating each time our friends had another action.
Now we have to process our tweets facebook posts.
%spark
import org.apache.streams.converter.ActivityConverterProcessor
import org.apache.streams.facebook.processor.FacebookTypeConverter
import org.apache.streams.core.StreamsProcessor
import org.apache.streams.pojo.json.Activity
import scala.collection.JavaConverters
import scala.collection.JavaConversions._
import org.apache.streams.pojo.json.Activity
import org.apache.streams.facebook.Post
import org.apache.streams.facebook.Page
//val converter = new ActivityConverterProcessor()
val converter = new FacebookTypeConverter(classOf[Post], classOf[Activity])
converter.prepare()
val status_datums = timeline_buf.map(x => new StreamsDatum(x))
val activity_datums = status_datums.flatMap(x => converter.process(x)).map(x => x.getDocument.asInstanceOf[Activity])
import org.apache.streams.jackson.StreamsJacksonMapper;
val mapper = StreamsJacksonMapper.getInstance();
val activitiesRDD = sc.parallelize(activity_datums.map(o => mapper.writeValueAsString(o)))
val activitiesDF = sqlContext.read.json(activitiesRDD)
activitiesDF.registerTempTable("activities")
The only line that changed here was
//val converter = new ActivityConverterProcessor() val converter = new FacebookTypeConverter(classOf[Post], classOf[Activity])
In the future, we won’t even need to change that line! But for now, we have to explicitly set the FacebookTypeConverter and let it know we are expecting to see Posts and we want Activities (which are Activity Streams 1.0 compliant.)
At this point it is pretty much the same as last time. Feel free to check out the schema of the activitiesDF by running
%spark.spark activitiesDF.printSchema()
If you are comparing to the tweet activities you collected before, you’ll notice there are some places where Facebook post-based activities contain more or less information, but at a high level the schema is similar: actor, likes, rebroadcasts, etc.
Let’s do a simple SQL query that won’t reveal the identity of any of my friends…
%spark.sql select location.city, count(id) from activities where location is not null group by location.city
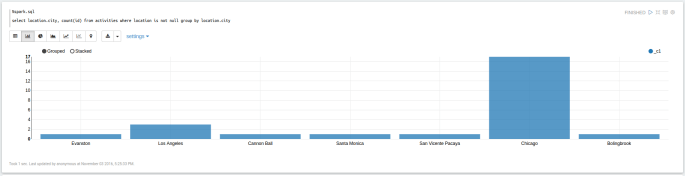
And here we see most of my friends and friends of friends of friend hail from Chicago, which makes sense because it is the best city in the country, and my friends aren’t dummies.
We’ll also need to do a little post-processing on some of these columns. For instance, times are all given as stings- so to work with them as dates we can do something like this:
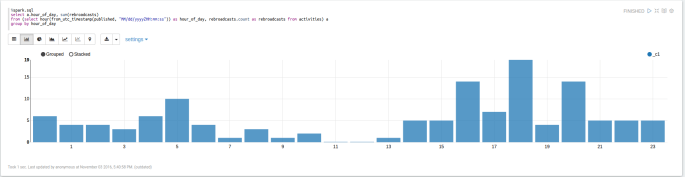
%spark.sql select a.hour_of_day, sum(rebroadcasts) from (select hour(from_utc_timestamp(published, "MM/dd/yyyyZHH:mm:ss")) as hour_of_day, rebroadcasts.count as rebroadcasts from activities) a group by hour_of_day

Do you know the origin story of the Apache Software Foundation? Let me tell you the short version: In the late 90s most of the internet was being powered by a web-server that no one was maintaining. It was a good product, but no one was feeding and caring for it (e.g. bug fixes, security updates). On BBS boards a number of people were talking about the issue, and how before too long they were going to have to start writing their own web-servers to replace it.
Around this time they realized, none of their respective companies competed based on web-servers; they were selling books, and flights, and hosting gifs of dancing hamsters. It made more sense for everyone to work together on a common web-server project- as a web server is something everyone needs, but no one uses for competitive advantage. Thus the Apache Web Server was born, and with it the Apache Software Foundation and the legally defensible, yet business friendly copyright.
This history lesson has a point, fast forward to present day and enter Apache Streams-incubating- lots of people from several industries are looking at social data from across multiple providers, everyone builds their own processors to transform into a useful format- that might be extracting text from tweets and Facebook posts. No one competes to do a ‘better job’ extracting data – its a straight forward task to connect to a providers API and reshaping a JSON into a table or other object- but it is something that everyone has to do. That’s where Apache Streams comes in.
Apache Streams is a package of tools for:
1. Connecting to a provider (e.g. Facebook or Twitter)
2. Retrieving data and reshaping it into a WC3 common format
3. Storing that data in a specified target (e.g. local file or database)
4. Doing this all in the JVM or a distributed engine (e.g. Apahce Flink or Apache Spark)
5. Much of this can be done with JSON configurations
We are going to write code to build this stream, but soon (upcoming post) we will show how to do it code free.
High level, Apache Streams is a framework that collects data from multiple social media providers, transform the data into a common, WC3 backed, format known as Activity Streams, and persist the data to multiple endpoints (e.g. files or databases).
It is also possible to use Apache Streams inline with regular Java/Scala code, which is what we will be demonstrating here today.
This post assuming you have Apache Zeppelin installed. Other posts on this blog explain how to setup up Zeppelin on clusters- you don’t need any of that. A local version of Zeppelin will work just find for what we’re about to do- see the official Zeppelin side for getting started
%spark.dep interpreter.This is the fail-safe method- however it relies on the deprecated %dep interpreter.
In the first paragraph of the notebook enter the following:
%spark.dep
z.addRepo("apache-snapshots").url("https://repository.apache.org/content/repositories/snapshots").snapshot()
z.load("org.apache.streams:streams-provider-twitter:0.4-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-converters:0.4-incubating-SNAPSHOT")
What we’ve done here is add the Apache Snapshots repository, which contains the Streams 0.4 Snapshots. A Snapshot is a most up-to-date version of a project. It’s not production grade but it has all of the latest and greatest features- unstable though they may be. At the time of writing Apache Streams is in the process of releasing 0.4.
If you get an error:
Must be used before SparkInterpreter (%spark) initialized Hint: put this paragraph before any Spark code and restart Zeppelin/Interpreter
Go to the interpreters page and restart the interpreter. (Click on “Anonymous” at the top right, a drop down menu will pop up, click on “Interpreters”, then at the new page search or scroll down to “Spark”. In the top right of the Spark interpreter tile there are three buttons, “Edit”, “Restart”, “Remove”. Click “Restart” then try running the paragraph again.
Follow the directions directly above for accessing the interpreter config GUI in Zeppelin. This time however, click “Edit”.
You will see Properties and Values. Scroll down and find the property:
zeppelin.dep.additionalRemoteRepository
In the Values, add the following code.
apache-snapshots,https://repository.apache.org/content/repositories/snapshots,true;
This step is equivalent to the z.addRepo(... line in the other method.
Now scroll down past the Properties and Values to the Dependencies section. In the Artifact section, add org.apache.streams:streams-provider-twitter:0.4-incubating-SNAPSHOT and org.apache.streams:streams-converters:0.4-incubating-SNAPSHOT, hit the little “+” button to the right after adding each. Finally save the changes (little button at bottom), which will restart the interpreter.
Each provider will have its own method for authenticating the calls you make for data, and its own process for granting credentials. In the case of Twitter, go to https://apps.twitter.com/.
There are several great blog posts you can find if you Google “create twitter app”. I’ll leave you to go read and learn. It’s a fairly painless process.
When you create the app, or if you already have an app- we need the following information:
– Consumer Key
– Consumer Secret
– Access Token
– Access Token Secret
First we are going to use the Apache Zeppelin’s Dynamic Forms to make it easy for users to copy and paste their Twitter Credentials into the program. Could you hard code your credentials? Sure, but this is a demo and we’re showing off.
The UserID is who we are going to follow. It should work with User ID’s or Twitter handles, however at the time of writing there is a bug where only UserIDs are available. In the mean time, use an online tool to convert usernames into IDs
You’ll see that we are simply getting values to fill into a string that looks sort of like a JSON called hocon. This config string, is the makings of the config JSONs that would allow you to define a Stream with out very little code. For the sake of teaching however, we’re going to cut code anyway.
Full setup Paragraph
%spark
val consumerKey = z.input("ConsumerKey", "")
val consumerSecret = z.input("ConsumerSecret", "")
val accessToken = z.input("AccessToken", "")
val accessTokenSecret = z.input("AccessTokenSecret", "")
val userID = z.input("UserID", "")
val hocon = s"""
twitter {
oauth {
consumerKey = "$consumerKey"
consumerSecret = "$consumerSecret"
accessToken = "$accessToken"
accessTokenSecret = "$accessTokenSecret"
}
retrySleepMs = 5000
retryMax = 250
info = [ $userID ]
}
"""
Note: Becareful when sharing this notebook, your credentials (the last ones used) will be stored in the notebook, even though they are not hard-coded.
We want to collect tweets, transform them into ActivityStreams objects, and persist the objects into a Spark DataFrame for querying and analytics.
After taking care of our imports, we will create an ArrayBuffer to which we will add tweets. Note, if you have any problems with the imports- check that you have done Step 1 correctly.
val timeline_buf = scala.collection.mutable.ArrayBuffer.empty[Object]
Next, we are going to parse the config string we created in the last step into a ComponentConfigurator which will be used to setup the Stream. Again, this all could be handled by Streams its self, we are literally recreating the wheel slightly for demonstration purposes.
val typesafe = ConfigFactory.parseString(hocon) val config = new ComponentConfigurator(classOf[TwitterUserInformationConfiguration]).detectConfiguration(typesafe, "twitter");
In the remaining code, we create a Streams provider from our config file, run it and collect tweets into our array buffer.
Full paragraph worth of code for copy+paste
"%spark
import com.typesafe.config._
import java.util.Iterator
import org.apache.streams.config._
import org.apache.streams.core._
import org.apache.streams.twitter.TwitterUserInformationConfiguration
import org.apache.streams.twitter.pojo._
import org.apache.streams.twitter.provider._
val timeline_buf = scala.collection.mutable.ArrayBuffer.empty[Object]
val typesafe = ConfigFactory.parseString(hocon)
val config = new ComponentConfigurator(classOf[TwitterUserInformationConfiguration]).detectConfiguration(typesafe, "twitter");
val provider = new TwitterTimelineProvider(config);
provider.prepare(null)
provider.startStream()
while(provider.isRunning()) {
val resultSet = provider.readCurrent()
resultSet.size()
val iterator = resultSet.iterator();
while(iterator.hasNext()) {
val datum = iterator.next();
//println(datum.getDocument)
timeline_buf += datum.getDocument
}
}
This is only a few lines of fairly self evident code. We create an ActivityConverterProcessor() and call the prepare method.
Recall, our timeline_buf was an ArrayBuffer of tweets- we are going to map each tweet into a StreamsDatum, because that is the format the converter expects for input. You can see on the next line our converter processes StreamsDatums.
The net result of this block is a scala.collection.mutable.ArrayBuffer[org.apache.streams.pojo.json.Activity] called activity_datums.
%spark import org.apache.streams.converter.ActivityConverterProcessor import org.apache.streams.core.StreamsProcessor import org.apache.streams.pojo.json.Activity import scala.collection.JavaConverters import scala.collection.JavaConversions._ val converter = new ActivityConverterProcessor() converter.prepare() val status_datums = timeline_buf.map(x => new StreamsDatum(x)) val activity_datums = status_datums.flatMap(x => converter.process(x)).map(x => x.getDocument.asInstanceOf[Activity])
This is more of a Spark / Apache Zeppelin trick than anything else. The StreamsJacksonMapper converts an Activity Stream Object into a JSON. We create activitiesRDD as an org.apache.spark.rdd.RDD[String] and in the next two lines create a DataFrame and register it as a temp table, in the usual ways.
%spark
import org.apache.streams.jackson.StreamsJacksonMapper;
val mapper = StreamsJacksonMapper.getInstance();
val activitiesRDD = sc.parallelize(activity_datums.map(o => mapper.writeValueAsString(o)))
val activitiesDF = sqlContext.read.json(activitiesRDD)
activitiesDF.registerTempTable("activities")
Zeppelin is so fun, because now we can use regular SQL in the next paragraph to explore this table- try this one on for size:
%spark.sql select ht, count(id) as mentions from ( select explode(hashtags) as ht, id from activities ) a group by ht order by mentions desc
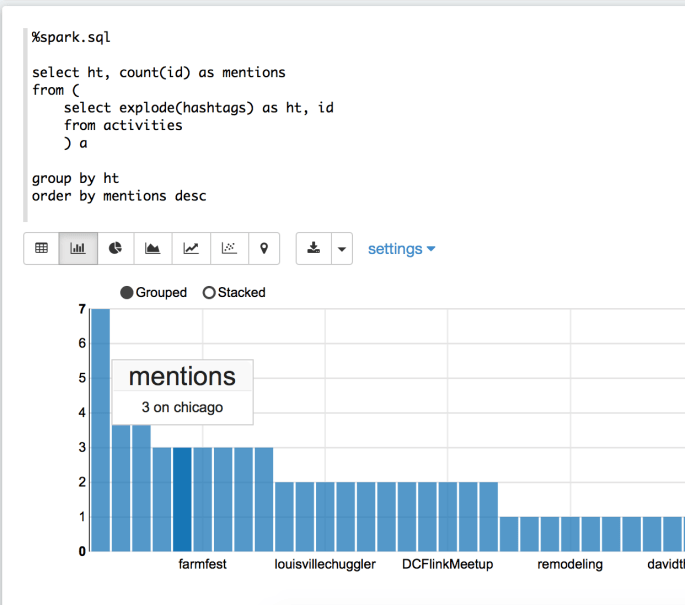
This query gives us a county by hashtag. There are two thing you’ll want to review regarding SparkSQL and querying JSONs.
– explode a row is with an array of length N it turned into N new rows, one for each element in N.
– To query a nested column use the style super_col.nested_col
Consider the following:
%spark activitiesDF.printSchema()
Outputs this:
root |-- actor: struct (nullable = true) | |-- displayName: string (nullable = true) | |-- extensions: struct (nullable = true) | | |-- favorites: long (nullable = true) | | |-- followers: long (nullable = true) | | |-- location: string (nullable = true) | | |-- posts: long (nullable = true) | | |-- screenName: string (nullable = true) ...
I truncated the output. The point is, if I wanted to query displayName and how many followers the person had I could do something like this.
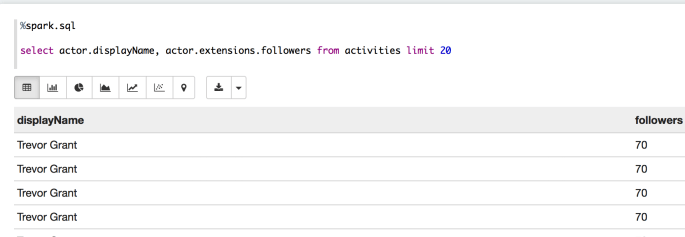
%spark.sql select actor.displayName, actor.extensions.favorites from activities limit 20
This query wasn’t very interesting because all of the rows were me, and 70 (my followers count).
Another dude’s blog post on querying JSONs, which candidly I didn’t even read
Apache Streams is an exciting young project that has the opportunity to really do some good in the world, by way of reducing wasteful redundancy (everyone has to write their own methods for collecting and homogenizing social media data).
Now you may be thinking- that was a lot of extra work to collect and visualize some tweets. I say to you:
1 – It wasn’t that much extra work
2 – Your tweets are now in Activity Streams which can be easily combined with Facebook / YouTube / GooglePlus / etc. data.
Hopefully this is going to be the first in a series of blog posts that will build on each other. Future blog posts will show how to connect other service providers and eventually we will build a collection of tools for collecting and analyzing data about your own social foot print. The series will culminate in a collection of Zeppelin Notebooks that allow the use to build an entire UI backed by Streams.

In this post we’re going to really show off the coolest (imho) use-case of Apache Mahout – roll your own distributed algorithms.
All of these posts are meant for you to follow-along at home, and it is entirely possible, you don’t have access to a large YARN cluster. That’s OK. Short story- they’re free on IBM’s BlueMix, where you can:
1. Sign up for a free 30-day account
2. Setup a 5-Node BigInsights (IBMs Hadoop Distro) on Cloud
3. Install Apache Zeppelin and Apache Mahout
4. Run an absurdly large OLS algorithm
The benefit of using a Hadoop as a Service environment is that for analytics, our dataset might not be HUGE enough that uploading is prohibitive, but big enough that we need more horse power than a single node can provide. Being able to spool up a cluster, upload a few files, do some work on it with 5 nodes/240GB RAM/ 48 Virtual processors- and then throw the environment away has a lot of use cases.
In this post we’re doing to write an Ordinary Least Squares algorithm, and then run it on a dataset of 100 million observations by 100 columns (dense).
This is a simplest of algorithms to get you started. Once you have this power at your finger tips, implement any algorithm you find specified in matrix form (which is most of them in academic papers) in Spark or Flink with ease. No longer are you tied to what ever the powers that be running SparkML and FlinkML decide to implement!
Disclosure: I’m working for IBM now, this isn’t an unsolicited sales pitch. The notebook available for part 4 will be available and will run on any Zeppelin instance (assuming you’ve followed the directions for setting up Mahout on Apache Spark listed in a previous post). If you are running Zeppelin locally, you also won’t be able to go as big as we do.
In short IBM Big Insights on Cloud is Hadoop-as-a-Service. It’s also fairly simple to setup.
Log in to BlueMix. In the navigation bar you should see “Catalog”. Click that, and then search “BigInsights”.
There are a few different UIs floating around at the moment, if you can’t find a way to create BigInsights, this link might help (must be logged in). Link
Click on BigInsights. In the next window, there should be a button that says ‘Create’ somewhere towards the right or bottom-right. (Old vs. new UI). From this point on, everything should look the same, so I’ll post more screen shots.
On the next screen click “Open”, and on the screen following that click “New Cluster”.
You should now be at a screen that looks like this:
The cluster name/ username / password don’t really matter.
In the following section, make sure to set the following:
IOP 4.2 (4.3 has Spark 2.0- gross).Spark is checked.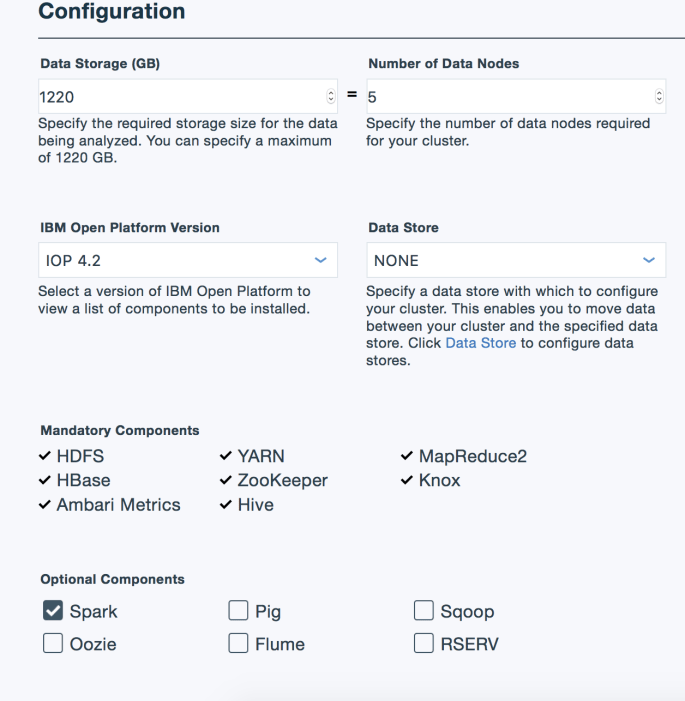
Click “Create” and then go grab some coffee or whatever. It will take about 5-10 minutes to setup.
After you click create you’ll be taken to a screen talking about your cluster.
In the top center you will see SSH Host and a value below that looks something like bi-hadoop-prod-XXXX.bi.services.us-south.bluemix.net, where the XXXX will be four numbers. You will need this value for the next step.
As a proud new IBM employee, I get unfettered access to these little clusters, to celebrate I’ve done a little Python witchcraft for quickly installing and my favorite services into BigInsights Cloud instances. These scripts also open up some ports in the firewall as needed for WebUIs (especially on Zeppelin, Apache NiFi, and Apache Flink).
The scripts in essence do the following:
– ssh in to the cluster
– download the binaries of the desired program (Zeppelin, NiFi, Flink, etc.)
– untar the program
– Upload some config files specific to BigInsights
– Start the service
– If a WebUI is necessary, a BlueMix app will be created which establishes an ssh tunnel between the world wide web and the port of the service (e.g. 8080 for Zeppelin).
Skip to the end of this section to see what I mean regarding the BlueMix app.
rawkintrevo’s scripts for installing extra services on BigInsights Cloud on github
The following assumes you are running on some sort of Ubuntu. The principals are the same, but you might need to take different steps to make this work on CentOS or OSX.
Obviously you need Python.
You also need the Python modules paramiko and scp, which are used for using ssh with Python. To install these in Ubunbu, from the command line run:
– sudo apt-get install python-paramiko
– sudo apt-get install python-scp
Next you will need to install Cloud Foundry and IBM’s Cloud Foundry bonus packs.
On Ubuntu, it’s going to look something like this-
Download Cloud Foundry Installer All Installers:
wget https://cli.run.pivotal.io/stable?release=debian64&version=6.22.1&source=github-rel
Unpack and install Cloud Foundry:
sudo dpkg -i ./cf-cli-*.deb && apt-get install -f
Set BlueMix Plugin Registry Endpoint:
cf add-plugin-repo bluemix-cf-staging https://plugins.ng.bluemix.net
Install BlueMix Plugins:
cf install-plugin active-deploy -r bluemix-cf-staging cf install-plugin bluemix-admin -r bluemix-cf-staging
Login to BlueMix via CloudFoundry:
cf login -a https://api.ng.bluemix.net
Now, clone my BlueMix extra services repo:
git clone https://github.com/rawkintrevo/bluemix-extra-services
In ./bluemix-extra-services you’ll find a script example_zeppelin_mahout.py. Open it up and set the following variables:
– APP_PREFIX : Whatever you set this to, Zeppelin will become available at http://APP_PREFIX-zeppelin.mybluemix.net
– SERVER : The name of the SSH Host from the end of Step 2. (not the name you assigned but the ssh address!)
– USERNAME : Username you entered when you created the server
– PASSWORD : Password you entered when you created the server
You’ll see some commented out section about S3 notebooks. BigInsights free clusters only persist for 14 days. When they expire- so do all of your notebooks, if not persisted. You can use AWS S3 to persist notebooks so they always pop up when create a new cluster. If you have an AWS account, you can create a bucket, and set S3_BUCKET to that value. In that bucket create a folder, set S3_USERNAME to whatever that folder is called. In that folder, create a folder called notebook. There is a link also commented out that explains this further. A little ways down you will see a line commented out z.setS3auth(S3_USERNAME, S3_BUCKET). Uncomment that line to have the script update the config files to use your S3 bucket at a notebook repository.
Finally, in S3. Click on your name at the top right, there will be a drop down. Click on “Security and Credentials”. A window will pop up, click “Continue …”. In the page in the center, click on “Access Keys (Access Key ID and Secret Access Key)”. Click on the blue button that says, “Create New Access Key”. Click on “Download key file”. Save the file as /path/to/bluemix-extra-services/data/resources/aws/rootkey.csv.
These steps are required. That makes this demo a bit more tedious, but in general is good, because then all your Zeppelin notebooks follow you where ever you go. (In the future I’ll probably update so this isn’t required, I’ll update the post then.)
NOTE on S3 charges Using S3 will incur a cost… My notebooks cost me about 14 cents per month.
The important thing to do before running this script is to make sure your cluster is fully set up. To do this, in the browser tab where you created your cluster, click the little back arrow to get to the Cluster list. You will have one cluster listed, named what ever you named it. It should have a little green circle and say “Active”. If it is a yellow circle and says “Pending”, wait a little longer or hit the refresh button at the top of the list. If it is a red circle and says “Failed” has happened to me about one time in 100, hover over the little gear to the right, click “Delete Cluster”, then create a new one again. If that happens be advised your SSH Host will have changed.
Once the cluster is active and you have updated and saved the Python script, run it- it will give you some standard out that should end in
webapp should be available soon at `http://APP_PREFIX-zeppelin.mybluemix.net
where APP_PREFIX is whatever you described it as.
This script is downloading various packages, uploading config files, and finally starting a simple python web app that establishes an SSH tunnel from the webapp to the webUI of the service on the BigInsights cloud cluster.
More information on Bluemix Apps
So you’ve made it this far, eh? Well done. Crack a beer- the rest is pretty easy. Apache Mahout is a library that allows you to quickly ‘roll your own’ algorithms based on matrix representations, and run them on your favorite distributed engine (assuming that engine is either Apache Spark, Apache Flink, or H20).
Now- we’re assuming you followed Step 3. to create a YARN cluster, and as such you have a Spark interpreter with all of the appropriate Mahout dependencies and settings. If you didn’t follow step 3, that’s ok- just make sure to create the Mahout interpreter following the steps found in this previous post.
The first paragraph you need to run when using the Mahout interpreter in Zeppelin imports Mahout and sets the distributed context.
%sparkMahout import org.apache.mahout.math._ import org.apache.mahout.math.scalabindings._ import org.apache.mahout.math.drm._ import org.apache.mahout.math.scalabindings.RLikeOps._ import org.apache.mahout.math.drm.RLikeDrmOps._ import org.apache.mahout.sparkbindings._ implicit val sdc: org.apache.mahout.sparkbindings.SparkDistributedContext = sc2sdc(sc)
The example we are going to do today very closely follows the Playing With the Mahout Shell post from the Mahout website, except with a twist. In our version we are going to use import org.apache.spark.mllib.util.LinearDataGenerator to create a very large data set to crunch.
%sparkMahout import org.apache.spark.mllib.util.LinearDataGenerator val n = 100000000 val features = 100 val eps = 0.1 // i'm guessing error term, poorly documented val partitions = 5500 val intercept = 10.0 val synDataRDD = LinearDataGenerator.generateLinearRDD(sc, n, features, eps, partitions, intercept)
Now we have a very large dataset, we need to convert it into a Mahout Distribute Row Matrix (think the Mahout equivelent of a RDD). A good primer on Mahout can be found here.
%sparkMahout
val tempRDD = synDataRDD.zipWithIndex.map( lv => {
val K = lv._2.toInt
val x = new DenseVector(lv._1.features.toArray )
//x = sparkVec2mahoutVec( lv._1.features ) // still doesn't serialize
val y = lv._1.label
(K, (y, x))
}).persist
println("----------- Creating DRMs --------------")
// temp RDD to X an y
val drmRddX:DrmRdd[Int] = tempRDD.map(o => (o._1, o._2._2))
val drmX = drmWrap(rdd= drmRddX)
val drmRddY:DrmRdd[Int] = tempRDD.map(o => (o._1, new DenseVector( Array(o._2._1) )))
val drmy = drmWrap(rdd= drmRddY)
Also note, the only reason we are using Spark instead of Flink here, is that SparkML comes with this nice linear data generator. Assuming you were loading your data from some other source, the following will code will run on Mahout on Spark OR Mahout on Flink.
For those a little rusty on Ordinary Least Squares method of regression:
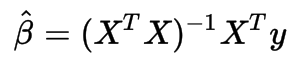
%sparkMahout val drmXtX = drmX.t %*% drmX val drmXty = drmX.t %*% drmy val beta = solve(drmXtX, drmXty)
And that’s it. An R-Like DSL for Scala that runs inside your Spark code and can be copy-pasted to Flink code.
Play with the paragraph that synthesizes data. This is a good exercise on how Spark partitioning strategies can affect performance. I played with it for an hour or so- 100 million rows by 100 columns was the largest I could get to run on the BigInsights Cloud ( which has approx 240GB RAM and 48 processors ).
In this post we spent a lot of time setting up an environment and not much time doing anything with it. The onus is now on you to go implement algorithms. In posts that follow, I intend to refer back to this post for setting up an environment that has the horse power to calculate big jobs. Because if you’re not going to be distributed then you have to ask your self, why not just do this in R?
tg
Two types of errors can happen in general:
– Zeppelin failed to start correctly
– The webapp failed to start
If you go to the address given and see a 404 error (make sure you typed it correctly), odds are the webapp failed. From the dashboard in BlueMix you should see your webapp, click on it and then click on logs. See if there are any clues.
If you go to the address and see a 502 error, Zeppelin didn’t start. Check the standard out from when you ran the program and look for errors.
If you go to the address and see a 503 error, the web app is tunneling correctly, but Zeppelin isn’t serving it data.
In a terminal ssh in to the cluster as follows:
ssh username@ssh-host
where username is the user name you picked in step 2, and ssh-host is the host given in SSH Host.
If you had a 502 error, from here you can manually start Zeppelin with
z*/bin/zeppelin-daemon.sh start
Then try the website again.
The BigInsights cluster is restrictive to say the least. Use tail to see the end of the logs.
tail z*/logs/*out -n 50
Look for something about AWS credentials not being accepted. If that happens, STOP ZEPPELIN
z*/bin/zeppelin-daemon.sh stop
Delete the zeppelin directory
rm -rf zeppelin-0.7.0-SNAPSHOT
Double check the rootkey.csv (maybe re download?) and run the python script again.
If you don’t see anything, at this point it is just standard Zeppelin troubleshooting.
