
In out last adventure we got did a basic example of Apache Streams with Twitter data. This week we’re going to extend that example with Facebook data! Also note, if this seems a little light it is because it’s not that different from the last post and the full explanations are there. Our goal here is not to explain all of Apache Streams (last week) but to begin branching out into other providers.
Getting credentialed through Facebook
The first step in any new provider is going to be to go get credentials. To get Facebook credentials you’ll need to visit Facebook App Dashboard. Once you get there and sign up, you’ll need to click “Add new App” (top right). After you’ve create the new app click “Settings”, in the panel to right. Here you will see the “AppID”, and if you click “Click show to see App Secret”, you’ll have two important strings you’re going to need soon.
The final piece of credentials you’ll need to set up is a userAccessToken. The easiest way to do this is to go to Graph API Explorer. These are temporary tokens that expire quickly (after an hour or so). This isn’t a “production” grade approach, but it is a good way to test things out and get going. Persistent tokening with Facebook is out of scope of this blog post and things which I care about at this point in my life.
Setting up the Stream
First you’ll need to add some dependencies, including the Facebook provider jar:
%spark.dep
z.reset()
z.addRepo("apache-snapshots").url("https://repository.apache.org/content/repositories/snapshots").snapshot()
z.load("org.apache.streams:streams-provider-facebook:0.4-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-converters:0.4-incubating-SNAPSHOT")
Next we create a paragraph to make a cute little GUI for entering our credentials.
%spark.spark
val appId = z.input("appId", "")
val appSecret = z.input("appSecret", "")
val userAccessToken = z.input("userAccessToken", "")
That’s going to create a from where you (or your friends) can copy paste their credentials into.

You’ll also want all of your inputs… and there are a LOT. (Likely not all necessary).
%spark.spark import com.typesafe.config._ import org.apache.streams.config._ import org.apache.streams.converter.ActivityConverterProcessor import org.apache.streams.core.StreamsProcessor import org.apache.streams.core._ import org.apache.streams.facebook._ import org.apache.streams.facebook.FacebookUserInformationConfiguration import org.apache.streams.facebook.FacebookUserstreamConfiguration import org.apache.streams.facebook.Page import org.apache.streams.facebook.Post import org.apache.streams.facebook.processor.FacebookTypeConverter import org.apache.streams.facebook.provider.FacebookFriendFeedProvider import org.apache.streams.jackson.StreamsJacksonMapper; import org.apache.streams.pojo.json.Activity import scala.collection.JavaConverters import scala.collection.JavaConversions._ import java.util.Iterator
Next we’ll create the config files. We dynamically create this string based on the values we enter at our little GUI we made. The info section is supposed list which users your are interested in. I think for this provider it is not important especially considering the way we got our AccessToken. In this case it basically just gives you everything you are entitled to and nothing else. Specifically this provider gives you a stream of everything your friends are doing.
%spark
val credentials =
s"""
{
facebook {
oauth {
appId = "$appId"
appSecret = $appSecret
userAccessToken = $userAccessToken
}
info = [
rawkintrevo
]
}
}
"""
val credentialsConfig = ConfigFactory.parseString(credentials)
val typesafe = ConfigFactory.parseString(credentials)
val config = new ComponentConfigurator(classOf[FacebookUserstreamConfiguration]).detectConfiguration(typesafe, "facebook");
val provider = new FacebookFriendFeedProvider(config, classOf[org.apache.streams.facebook.Post] );
val timeline_buf = scala.collection.mutable.ArrayBuffer.empty[Object]
provider.prepare()
provider.startStream()
This should look very similar to the setup we did for the Twitter stream, except of course we are using FacebookUserstreamConfiguration and the FacebookFriendFeedProvider classes, and our stream will consist of org.apache.streams.facebook.Posts
%spark
//while(provider.isRunning()) {
for (i <- 0 to 20) {
val resultSet = provider.readCurrent()
resultSet.size()
val iterator = resultSet.iterator();
while(iterator.hasNext()) {
val datum = iterator.next();
//println(datum.getDocument)
timeline_buf += datum.getDocument
}
println(s"Iteration $i")
}
provider.cleanUp()
The key difference here is that we stop running after 40 iterations. That should be PLENTY of data. If we use the while loop, this would run forever updating each time our friends had another action.
Now we have to process our tweets facebook posts.
%spark
import org.apache.streams.converter.ActivityConverterProcessor
import org.apache.streams.facebook.processor.FacebookTypeConverter
import org.apache.streams.core.StreamsProcessor
import org.apache.streams.pojo.json.Activity
import scala.collection.JavaConverters
import scala.collection.JavaConversions._
import org.apache.streams.pojo.json.Activity
import org.apache.streams.facebook.Post
import org.apache.streams.facebook.Page
//val converter = new ActivityConverterProcessor()
val converter = new FacebookTypeConverter(classOf[Post], classOf[Activity])
converter.prepare()
val status_datums = timeline_buf.map(x => new StreamsDatum(x))
val activity_datums = status_datums.flatMap(x => converter.process(x)).map(x => x.getDocument.asInstanceOf[Activity])
import org.apache.streams.jackson.StreamsJacksonMapper;
val mapper = StreamsJacksonMapper.getInstance();
val activitiesRDD = sc.parallelize(activity_datums.map(o => mapper.writeValueAsString(o)))
val activitiesDF = sqlContext.read.json(activitiesRDD)
activitiesDF.registerTempTable("activities")
The only line that changed here was
//val converter = new ActivityConverterProcessor() val converter = new FacebookTypeConverter(classOf[Post], classOf[Activity])
In the future, we won’t even need to change that line! But for now, we have to explicitly set the FacebookTypeConverter and let it know we are expecting to see Posts and we want Activities (which are Activity Streams 1.0 compliant.)
At this point it is pretty much the same as last time. Feel free to check out the schema of the activitiesDF by running
%spark.spark activitiesDF.printSchema()
If you are comparing to the tweet activities you collected before, you’ll notice there are some places where Facebook post-based activities contain more or less information, but at a high level the schema is similar: actor, likes, rebroadcasts, etc.
Let’s do a simple SQL query that won’t reveal the identity of any of my friends…
%spark.sql select location.city, count(id) from activities where location is not null group by location.city
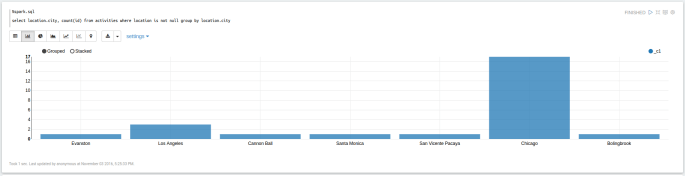
And here we see most of my friends and friends of friends of friend hail from Chicago, which makes sense because it is the best city in the country, and my friends aren’t dummies.
We’ll also need to do a little post-processing on some of these columns. For instance, times are all given as stings- so to work with them as dates we can do something like this:
%spark.sql select a.hour_of_day, sum(rebroadcasts) from (select hour(from_utc_timestamp(published, "MM/dd/yyyyZHH:mm:ss")) as hour_of_day, rebroadcasts.count as rebroadcasts from activities) a group by hour_of_day
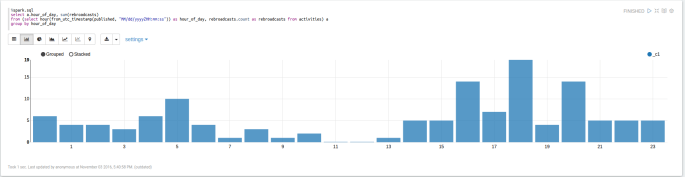
Notes
- Zeppelin’s Table API doesn’t handle new lines well. If you try to build a table of the messages, it’s not going to work out great. I leave it as an exercise to the user to clean that up.
