
Do you know the origin story of the Apache Software Foundation? Let me tell you the short version: In the late 90s most of the internet was being powered by a web-server that no one was maintaining. It was a good product, but no one was feeding and caring for it (e.g. bug fixes, security updates). On BBS boards a number of people were talking about the issue, and how before too long they were going to have to start writing their own web-servers to replace it.
Around this time they realized, none of their respective companies competed based on web-servers; they were selling books, and flights, and hosting gifs of dancing hamsters. It made more sense for everyone to work together on a common web-server project- as a web server is something everyone needs, but no one uses for competitive advantage. Thus the Apache Web Server was born, and with it the Apache Software Foundation and the legally defensible, yet business friendly copyright.
This history lesson has a point, fast forward to present day and enter Apache Streams-incubating- lots of people from several industries are looking at social data from across multiple providers, everyone builds their own processors to transform into a useful format- that might be extracting text from tweets and Facebook posts. No one competes to do a ‘better job’ extracting data – its a straight forward task to connect to a providers API and reshaping a JSON into a table or other object- but it is something that everyone has to do. That’s where Apache Streams comes in.
Apache Streams is a package of tools for:
1. Connecting to a provider (e.g. Facebook or Twitter)
2. Retrieving data and reshaping it into a WC3 common format
3. Storing that data in a specified target (e.g. local file or database)
4. Doing this all in the JVM or a distributed engine (e.g. Apahce Flink or Apache Spark)
5. Much of this can be done with JSON configurations
We are going to write code to build this stream, but soon (upcoming post) we will show how to do it code free.
About Apache Streams
High level, Apache Streams is a framework that collects data from multiple social media providers, transform the data into a common, WC3 backed, format known as Activity Streams, and persist the data to multiple endpoints (e.g. files or databases).
It is also possible to use Apache Streams inline with regular Java/Scala code, which is what we will be demonstrating here today.
Step 1. Configuring
This post assuming you have Apache Zeppelin installed. Other posts on this blog explain how to setup up Zeppelin on clusters- you don’t need any of that. A local version of Zeppelin will work just find for what we’re about to do- see the official Zeppelin side for getting started
Method 1- The %spark.dep interpreter.
This is the fail-safe method- however it relies on the deprecated %dep interpreter.
In the first paragraph of the notebook enter the following:
%spark.dep
z.addRepo("apache-snapshots").url("https://repository.apache.org/content/repositories/snapshots").snapshot()
z.load("org.apache.streams:streams-provider-twitter:0.4-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-converters:0.4-incubating-SNAPSHOT")
What we’ve done here is add the Apache Snapshots repository, which contains the Streams 0.4 Snapshots. A Snapshot is a most up-to-date version of a project. It’s not production grade but it has all of the latest and greatest features- unstable though they may be. At the time of writing Apache Streams is in the process of releasing 0.4.
If you get an error:
Must be used before SparkInterpreter (%spark) initialized Hint: put this paragraph before any Spark code and restart Zeppelin/Interpreter
Go to the interpreters page and restart the interpreter. (Click on “Anonymous” at the top right, a drop down menu will pop up, click on “Interpreters”, then at the new page search or scroll down to “Spark”. In the top right of the Spark interpreter tile there are three buttons, “Edit”, “Restart”, “Remove”. Click “Restart” then try running the paragraph again.
Method 2- The config GUI
Follow the directions directly above for accessing the interpreter config GUI in Zeppelin. This time however, click “Edit”.
You will see Properties and Values. Scroll down and find the property:
zeppelin.dep.additionalRemoteRepository
In the Values, add the following code.
apache-snapshots,https://repository.apache.org/content/repositories/snapshots,true;
This step is equivalent to the z.addRepo(... line in the other method.
Now scroll down past the Properties and Values to the Dependencies section. In the Artifact section, add org.apache.streams:streams-provider-twitter:0.4-incubating-SNAPSHOT and org.apache.streams:streams-converters:0.4-incubating-SNAPSHOT, hit the little “+” button to the right after adding each. Finally save the changes (little button at bottom), which will restart the interpreter.
Step 2. Getting credentials from Twitter
Each provider will have its own method for authenticating the calls you make for data, and its own process for granting credentials. In the case of Twitter, go to https://apps.twitter.com/.
There are several great blog posts you can find if you Google “create twitter app”. I’ll leave you to go read and learn. It’s a fairly painless process.
When you create the app, or if you already have an app- we need the following information:
– Consumer Key
– Consumer Secret
– Access Token
– Access Token Secret
Step 3. Configuring the Stream
First we are going to use the Apache Zeppelin’s Dynamic Forms to make it easy for users to copy and paste their Twitter Credentials into the program. Could you hard code your credentials? Sure, but this is a demo and we’re showing off.
The UserID is who we are going to follow. It should work with User ID’s or Twitter handles, however at the time of writing there is a bug where only UserIDs are available. In the mean time, use an online tool to convert usernames into IDs
You’ll see that we are simply getting values to fill into a string that looks sort of like a JSON called hocon. This config string, is the makings of the config JSONs that would allow you to define a Stream with out very little code. For the sake of teaching however, we’re going to cut code anyway.
Full setup Paragraph
%spark
val consumerKey = z.input("ConsumerKey", "")
val consumerSecret = z.input("ConsumerSecret", "")
val accessToken = z.input("AccessToken", "")
val accessTokenSecret = z.input("AccessTokenSecret", "")
val userID = z.input("UserID", "")
val hocon = s"""
twitter {
oauth {
consumerKey = "$consumerKey"
consumerSecret = "$consumerSecret"
accessToken = "$accessToken"
accessTokenSecret = "$accessTokenSecret"
}
retrySleepMs = 5000
retryMax = 250
info = [ $userID ]
}
"""
Note: Becareful when sharing this notebook, your credentials (the last ones used) will be stored in the notebook, even though they are not hard-coded.
Step 4. Writing the Pipeline
We want to collect tweets, transform them into ActivityStreams objects, and persist the objects into a Spark DataFrame for querying and analytics.
After taking care of our imports, we will create an ArrayBuffer to which we will add tweets. Note, if you have any problems with the imports- check that you have done Step 1 correctly.
val timeline_buf = scala.collection.mutable.ArrayBuffer.empty[Object]
Next, we are going to parse the config string we created in the last step into a ComponentConfigurator which will be used to setup the Stream. Again, this all could be handled by Streams its self, we are literally recreating the wheel slightly for demonstration purposes.
val typesafe = ConfigFactory.parseString(hocon) val config = new ComponentConfigurator(classOf[TwitterUserInformationConfiguration]).detectConfiguration(typesafe, "twitter");
In the remaining code, we create a Streams provider from our config file, run it and collect tweets into our array buffer.
Full paragraph worth of code for copy+paste
"%spark
import com.typesafe.config._
import java.util.Iterator
import org.apache.streams.config._
import org.apache.streams.core._
import org.apache.streams.twitter.TwitterUserInformationConfiguration
import org.apache.streams.twitter.pojo._
import org.apache.streams.twitter.provider._
val timeline_buf = scala.collection.mutable.ArrayBuffer.empty[Object]
val typesafe = ConfigFactory.parseString(hocon)
val config = new ComponentConfigurator(classOf[TwitterUserInformationConfiguration]).detectConfiguration(typesafe, "twitter");
val provider = new TwitterTimelineProvider(config);
provider.prepare(null)
provider.startStream()
while(provider.isRunning()) {
val resultSet = provider.readCurrent()
resultSet.size()
val iterator = resultSet.iterator();
while(iterator.hasNext()) {
val datum = iterator.next();
//println(datum.getDocument)
timeline_buf += datum.getDocument
}
}
Transforming Tweets into Activity Stream Objects
This is only a few lines of fairly self evident code. We create an ActivityConverterProcessor() and call the prepare method.
Recall, our timeline_buf was an ArrayBuffer of tweets- we are going to map each tweet into a StreamsDatum, because that is the format the converter expects for input. You can see on the next line our converter processes StreamsDatums.
The net result of this block is a scala.collection.mutable.ArrayBuffer[org.apache.streams.pojo.json.Activity] called activity_datums.
%spark import org.apache.streams.converter.ActivityConverterProcessor import org.apache.streams.core.StreamsProcessor import org.apache.streams.pojo.json.Activity import scala.collection.JavaConverters import scala.collection.JavaConversions._ val converter = new ActivityConverterProcessor() converter.prepare() val status_datums = timeline_buf.map(x => new StreamsDatum(x)) val activity_datums = status_datums.flatMap(x => converter.process(x)).map(x => x.getDocument.asInstanceOf[Activity])
Step 5. Visualizing the results
This is more of a Spark / Apache Zeppelin trick than anything else. The StreamsJacksonMapper converts an Activity Stream Object into a JSON. We create activitiesRDD as an org.apache.spark.rdd.RDD[String] and in the next two lines create a DataFrame and register it as a temp table, in the usual ways.
%spark
import org.apache.streams.jackson.StreamsJacksonMapper;
val mapper = StreamsJacksonMapper.getInstance();
val activitiesRDD = sc.parallelize(activity_datums.map(o => mapper.writeValueAsString(o)))
val activitiesDF = sqlContext.read.json(activitiesRDD)
activitiesDF.registerTempTable("activities")
Zeppelin is so fun, because now we can use regular SQL in the next paragraph to explore this table- try this one on for size:
%spark.sql select ht, count(id) as mentions from ( select explode(hashtags) as ht, id from activities ) a group by ht order by mentions desc
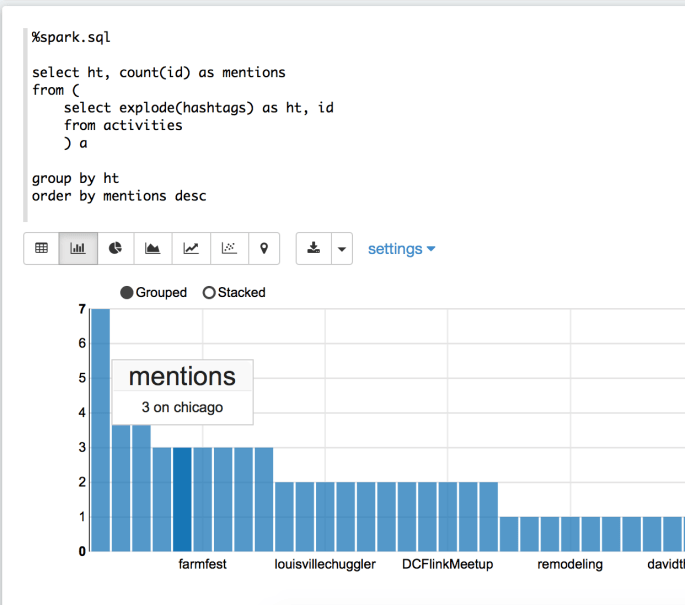
This query gives us a county by hashtag. There are two thing you’ll want to review regarding SparkSQL and querying JSONs.
– explode a row is with an array of length N it turned into N new rows, one for each element in N.
– To query a nested column use the style super_col.nested_col
Consider the following:
%spark activitiesDF.printSchema()
Outputs this:
root |-- actor: struct (nullable = true) | |-- displayName: string (nullable = true) | |-- extensions: struct (nullable = true) | | |-- favorites: long (nullable = true) | | |-- followers: long (nullable = true) | | |-- location: string (nullable = true) | | |-- posts: long (nullable = true) | | |-- screenName: string (nullable = true) ...
I truncated the output. The point is, if I wanted to query displayName and how many followers the person had I could do something like this.
%spark.sql select actor.displayName, actor.extensions.favorites from activities limit 20
This query wasn’t very interesting because all of the rows were me, and 70 (my followers count).
Another dude’s blog post on querying JSONs, which candidly I didn’t even read
Final Thoughts and next steps
Apache Streams is an exciting young project that has the opportunity to really do some good in the world, by way of reducing wasteful redundancy (everyone has to write their own methods for collecting and homogenizing social media data).
Now you may be thinking- that was a lot of extra work to collect and visualize some tweets. I say to you:
1 – It wasn’t that much extra work
2 – Your tweets are now in Activity Streams which can be easily combined with Facebook / YouTube / GooglePlus / etc. data.
Hopefully this is going to be the first in a series of blog posts that will build on each other. Future blog posts will show how to connect other service providers and eventually we will build a collection of tools for collecting and analyzing data about your own social foot print. The series will culminate in a collection of Zeppelin Notebooks that allow the use to build an entire UI backed by Streams.

One thought on “Dipping Your Toes in Apache Streams”