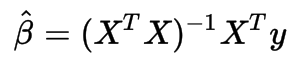or “how I accidentally enslaved humanity to the Machine Overlords”.
The Borg are a fictional group from the Sci-Fi classic, Star Trek, who among other things have a collective consciousness. This creates a number of problems for the poor humans (and other species) that attempt to resist the Borg, as they are extremely adaptive. When a single Borg Drone learns something, its knowledge is very quickly propagated through the collective, presumably subject to network connectivity issues, and latency.
Here we create a system for an arbitrary number edge devices to report sensor data, a central processor to use the data to understand the environment the edge devices are participating in, and finally to make decisions / give instructions back to the edge device. This is in essence what the Borg are doing. Yes, there are some interesting biological / cybernetic integrations, however as far as the “hive mind” aspect is concerned, this is basic principles in play.
I originally built this toy to illustrate that “A.I.” has three principle components: Real time data going into a system, an understanding of the environment is reached, a decision is made. (1) Real Time artifical intelligence, like the “actual” intelligence it supposedly mimics is not making E.O.D. batch decisions. (2) In real time the system is aware of what is happening around it- understanding its environment and then using that understanding to (3) make some sort of decision about how to manipulate that environment. Read up on definitions of intelligence, a murky subject itself.
Another sweet bonus, I wanted to show that sophisticated A.I. can be produced with off-the-shelf components and a little creativity, despite what vendors want to tell you. Vendors have their place. It’s one thing to make something cool, another to productionalize it- and maybe you just don’t care enough. However, since you’re reading this- I hope you at least care a little.
Artificial Intelligence is by no means synonymous with Deep Learning, though Deep Learning can be a very useful tool for building A.I. systems. This case does real time image recognition, and you’ll note does not invoke Deep Learning or even the less buzz-worthy “neural nets” at any point. Those can be easily introduced to the solution, but you don’t need them.
Like the Great and Powerful Oz, once you pull back the curtain on A.I. you realize its just some old man who got lost and creatively used resources he had lying around to create a couple of interesting magic tricks.

System Architecture
OpenCV is the Occipital Lobe, this is where faces are identified in the video stream.
Apache Kafka is the nervous system, how messages are passed around the collective. (If we later need to defeat the Borg, this is probably the best place to attack- presuming we of course we aren’t able to make the drones self aware).

Apache Flink is the collective consciousness of our Borg Collective, where thoughts of the Hive Mind are achieved. This is probably intuitive if you are familiar with Apache Flink.
Apache Solr is the store of the “memories” of the collective consciousness.
The Apache Mahout library is the “higher order brain functions” for understanding. It is an ideal choice as it is well integrated with Apache Flink and Apache Spark
Apache Spark with Apache Mahout gives our creation a sense of conext, e.g. how do I recognize faces? It quickly allows us to bootstrap millions of years of evolutionary biological processes.
A Walk Through
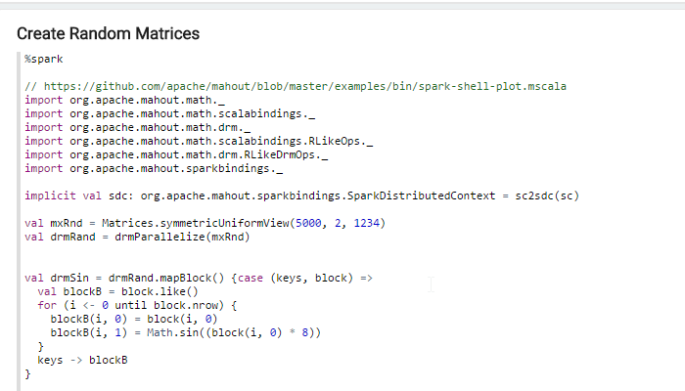
(1) Spark + Mahout used to calculate eigenfaces (see previous blog post).
(2) Flink is started, it loads the calculated eigenfaces from (1)
(3) A video feed is processed with OpenCV .
(4) OpenCV uses Haar Cascade Filters to detect faces.
(5) Detected faces are turned in to Java Buffered Images, greyscaled and size-scaled to the size used for Eigenface calculations and binarized (inefficient). The binary arrays are passed as messages to Kafka.
(6) Flink picks up the images, converts them back to buffered images. The buffered image is then decomposed into linear a linear combination of the Eigenfaces calculated in (1).
(7) Solr is queried for matching linear combinations. Names associated with best N matches are assigned to each face. I.e. face is “identified”… poorly. See next comments.
(8) If the face is of a “new” person, the linear combinations are written to Solr as a new potential match for future queries.
(8) Instructions for edge device written back to Kafka messaging queue as appropriate.
Problems
A major problem we instantly encountered was that sometimes OpenCV will “see” faces that do not exist, as patterns in clothing, shadows, etc. To overcome this we use Flink’s sliding time window and Mahout’s Canopy clustering. Intuitively, faces will not momentarily appear and disappear within a frame, cases where this happens are likely errors on the part of OpenCV. We create a short sliding time window and cluster all faces in the window based on their X, Y coordinates. Canopy clustering is used because it is able to cluster all faces in one pass, reducing the amount of introduced latency. This step happens between step (6) and (7)
In the resulting clusters there are either lots of faces (a true face) or a very few faces (a ghost or shadow, which we do not want). Images belonging to the former are further processed for matches in step (7).
Another challenge is certain frames of a face may look like someone else, even though we have been correctly identifying the face in question in nearby frames. We use our clusters generated in the previous hack, and decide that people do not spontaneously become other people for an instant and then return. We take our queries from step 7 and determine who the person is based on the cluster, not the individual frames.
Finally, as our Solr index of faces grows, our searches in Solr will become less and less effecient. Hierarchical clustering is believed to speed up these results and be akin to how people actually recognize each other. In the naive form, for each Solr Query will scan the entire index of faces looking for a match. However we can clusters the eigenface combinations such that each query will first only scan the cluster centriods, and then only consider eigenfaces in that cluster. This can potentially speed up results greatly.
Usecases
Borg
This is how the Borg were able to recognize Locutus of Borg.

Cylons
This type of system also was imperative for Cylon Raiders and Centurions to recognize (and subsequently not inadvertently kill) the Final Five.

Shorter Term
This toy was originally designed to work with the Petrone Battle Drones however as we see the rise of Sophia and Atlas, this technology could be employed to help multiple subjects with similar tasks learn and adapt more quickly. Additionally there are numerous applications in security (think network of CCTV cameras, remote locks, alarms, fire control, etc.)
Do you want Cylons? Because that’s how you get Cylons.
Alas, there is no great and powerful Oz. Or- there is, and …

References
Flink Forward, Berlin 2017
Slides Video (warning I was sick this day. Not my best work).
Lucene Revolution, Las Vegas 2017
Slides Video
PR Donating this to Apache Mahout
If you’re interested in contributing, please start here.