
I was at Apache Big Data last week and got to talking to some of the good folks at the Apache Mahout project. For those who aren’t familiar, Apache Mahout is a rich Machine Learning and Linear Algebra Library that originally ran on top of Apache Hadoop, and as of recently runs on top of Apache Flink and Apache Spark. It runs in the interactive Scala shell but exposes a domain specific language that makes it feel much more like R than Scala.
Well, the Apache Mahout folks had been wanting to build out some visualization capabilities comparable to matplotlib and ggplot2 (Python and R respectively). They had considered integrating with Apache Zeppelin and utilizing the AngularJS framework native to Zeppelin. We talked it out, and decided it made much more sense to simply use the matplotlib and ggplot2 features of Python and R, and Apache Zeppelin could to facilitate that somewhat cumbersome pipeline.
So I dinked around with it Monday and Tuesday, learning my way around Apache Mahout, and overcoming an issue with an upgrade I made when I rebuilt Zeppelin (in short I needed to refresh my browser cache…).
Without further ado, here is a guide on how to get started playing with Apache Mahout yourself!
Step 1. Clone / Build Apache Mahout
At the bash shell (e.g. command prompt, see my other blog post on setting up Zeppelin + Flink + Spark), enter the following:
git clone https://github.com/apache/mahout.git
cd mahout
mvn clean install -DskipTestsThat will install Apache Mahout.
Step 2. Create/Configure/Bind New Zeppelin Interpreter
Step 2a. Create
Next we are going to create a new Zeppelin Interpreter.
In the interpreters page, at the top right, you’ll see a button that says: “+Create”. Click on that.
We’re going to name this ‘spark-mahout’ (thought the name is not important).
On the interpreter drop-down we’re going to select Spark.
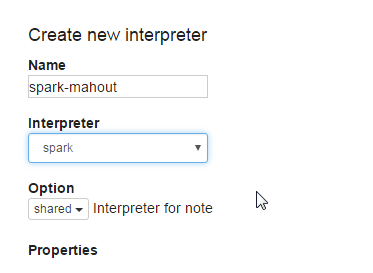
Step 2b. Configure
We’re going to add the following properties and values by clicking the “+” sign at the bottom of the properties list:
| Property | Value |
|---|---|
| spark.kryo.registrator | org.apache.mahout.sparkbindings.io.MahoutKryoRegistrator |
| spark.serializer | org.apache.spark.serializer.KryoSerializer |
| spark.kryo.referenceTracking | false |
| spark.kryoserializer.buffer | 300m |
And below that we will add the following artifacts to the dependencies (no value necessary for the ‘exclude’ field)
| Artifact | Exclude |
|---|---|
| /home/username/.m2/repository/org/apache/mahout/mahout-math/0.12.1-SNAPSHOT/mahout-math-0.12.1-SNAPSHOT.jar | |
| /home/username/.m2/repository/org/apache/mahout/mahout-math-scala_2.10/0.12.1-SNAPSHOT/mahout-math-scala_2.10-0.12.1-SNAPSHOT.jar | |
| /home/username/.m2/repository/org/apache/mahout/mahout-spark_2.10/0.12.1-SNAPSHOT/mahout-spark_2.10-0.12.1-SNAPSHOT.jar | |
| /home/username/.m2/repository/org/apache/mahout/mahout-spark-shell_2.10/0.12.1-SNAPSHOT/mahout-spark-shell_2.10-0.12.1-SNAPSHOT.jar | |
| /home/username/.m2/repository/org/apache/mahout/mahout-spark_2.10/0.12.1-SNAPSHOT/mahout-spark_2.10-0.12.1-SNAPSHOT-dependency-reduced.jar |
Make sure to click ‘Save’ when you are done. Also, maybe this goes without saying, maybe it doesn’t… but
make sure to change username to your actual username, don’t just copy and paste!
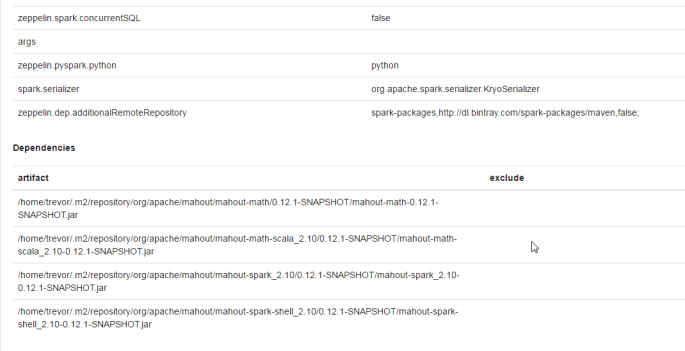
Step 2c. Bind
In any notebook in which you want to use the spark-mahout interpreter, not the regular old Spark one, you need to bind correct interpreter.
Create a new notebook, lets call it “[MAHOUT] Binding Example”.
In the top right, you’ll see a little black gear, click on it. A number of interpreters will pop up. You want to click on the Spark one at the top (such that is becomes un-highlighted) then click on the “spark-mahout” one toward the bottom. Finally drag the “spark-mahout” one up to the top. Finally, as always, click on ‘Save’.
Now, this notebook knows to use the spark-mahout interpreter instead of the regular spark interpreter (and so, all of the properties and dependencies you’ve added will also be used). You’ll need to do this for every notebook in which you wish to use the Mahout Interpreter!
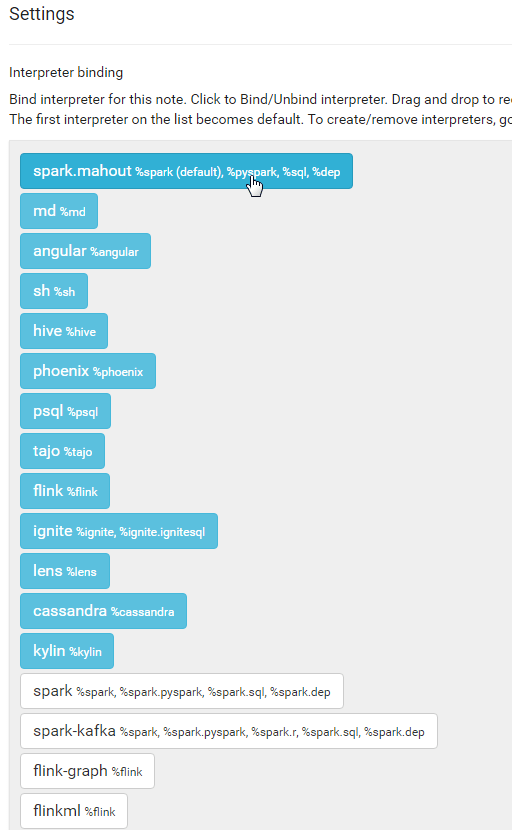
Step 2d. Setting the Environment
Back at the command prompt, we need to tweek the environment a bit. At the command prompt (assuming you are in the mahout directory still):
./bin/mahout-load-spark-env.sh
And then we’re going to export some environment variables:
export MAHOUT_HOME=[directory into which you checked out Mahout]
export SPARK_HOME=[directory where you unpacked Spark]
export MASTER=[url of the Spark master]
If you are going to be using Mahout often, it would be wise to add those exports to $ZEPPELIN_HOME/conf/zeppelin-env.sh so they are loaded every time.
Step 3. Mahout it up!
I don’t like to repeat other people’s work, so I’m going to direct you to another great article explaining how to do simple matrix based linear regression. https://mahout.apache.org/users/sparkbindings/play-with-shell.html
I’m going to do you another favor. Go to the Zeppelin home page and click on ‘Import Note’. When given the option between URL and json, click on URL and enter the following link:
That should run, and is in fact the Zeppelin version of the above blog post.
The key thing I will point out however is the top of the first paragraph:
import org.apache.mahout.math._
import org.apache.mahout.math.scalabindings._
import org.apache.mahout.math.drm._
import org.apache.mahout.math.scalabindings.RLikeOps._
import org.apache.mahout.math.drm.RLikeDrmOps._
import org.apache.mahout.sparkbindings._
implicit val sdc: org.apache.mahout.sparkbindings.SparkDistributedContext = sc2sdc(sc)
That is where the magic happens and introduces Mahout’s SparkDistributedContext and the R-like Domain Specific Language.
You know how in Scala you can pretty much just write whatever you want (syntactic sugar run-amok) well a domain specific language (or DSL) lets you take that even further and change the syntax even further. This is not a precisely accurate statement, feel free to google if you want to know more.
The moral of the story is: what was Scala, now smells much more like R.
Further, for the rest of this notebook, you can now use the Mahout DSL, which is nice because it is the same for Flink and Spark. What that means is you can start playing with this right away using Spark-Mahout, but when the Flink-Mahout comes online soon (and I promise to update this post showing how to hook it up) you can copy/paste your code to your Flink-Mahout paragraphs and probably run it a bunch faster.
The Main Event
So the whole point of all of this madness was to monkey-patch Mahout into R/Python to take advantage of those graphics libraries.
I’ve done you another solid favor. Import this notebook:
https://raw.githubusercontent.com/rawkintrevo/mahout-zeppelin/master/%5BMAHOUT%5D%5BPROVING-GROUNDS%5DSpark-Mahout%2Bggplot2.json
UPDATE 5-29-16: Originally, I had accidentally re-linked the first notebook (sloppy copy-paste on my part)- this one shows ggplot2 integration, e.g. the entire point of this Blog post…
Ignore the first couple of paragraphs (by the time you read this I might have (unlikely, lol) cleaned this notebook up and deleted).
There is a paragraph that Creates Random Matrices
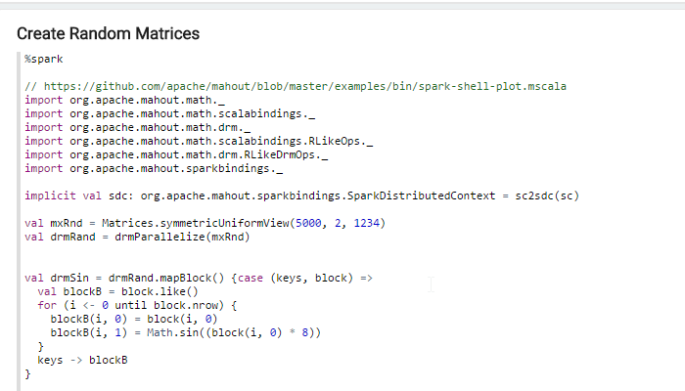
…yawn. You can grok it later. But again, notice those imports and creating the SparkDistributedContext. We’re using our SparkContext (sc ) that Zeppelin automatically creates in the paragraph to initialize this.
In the next paragraph we sample 1000 rows from the matrix. Why a sample? Well in theory the whole point of using Mahout is you’re going to be working with matrices much to big to fit in the memory of a single machine, much less graph them in any sort of meaningful way (think millions to trillions to bajillions of rows). How many do you really need. If you want to get a feel for the matrix as a whole, random sample. Depending on what you’re trying to do will determine how exactly you sample the matrix, just be advised- it is a nasty habit to think you are just going to visualize the whole thing (even though it is possible on these trivial examples). If that were possible in the first place on your real data, you’d have actually been better served to just used R to begin with…
The next paragraph basically converts the matrix into a tab-separated-file, except it is held as a string and never actually written to disk. This loop is effective, but not ideal. In the near future we hope to wrap some syntactic sugar around this, simply exposing a method on the matrix that spits out a sampled *.tsv. Once there exists a tab-separated string, we can add %table to the front of the string and print it- Zeppelin will automatically figure out this is supposed to be charted and you can see here how we could use Zeppelin’s predefined charts to explore this table.
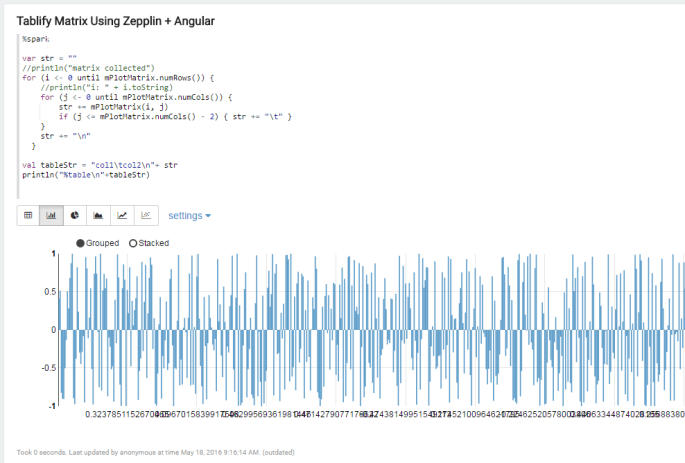
Keeping in mind this matrix was a sine function, this sampling looks more or less accurate. The Zeppelin graph is trying to take some liberties though and do aggregations on one of the columns. To be fair, we’re trying to do something weird here; something for which this chart wasn’t intended for.
Next, the tsv string is then stored in something known to Zeppelin as the ResourcePool. Almost any interpreter can access the resource pool and it is a great way to share data between interpreters.
Once we have a *.tsv in memory, and it’s in the resource pool, all that is left is to “fish it out” of the resource pool and load it as a dataframe. That is an uncommon but not altogether unheard of thing to do in R via the read.table function.
Thanks to all of the work done on the SparkR-Zeppelin integration, we can now load our dataframe and simply use ggplot2 or a host of other R plotting packages (see the R tutorial).
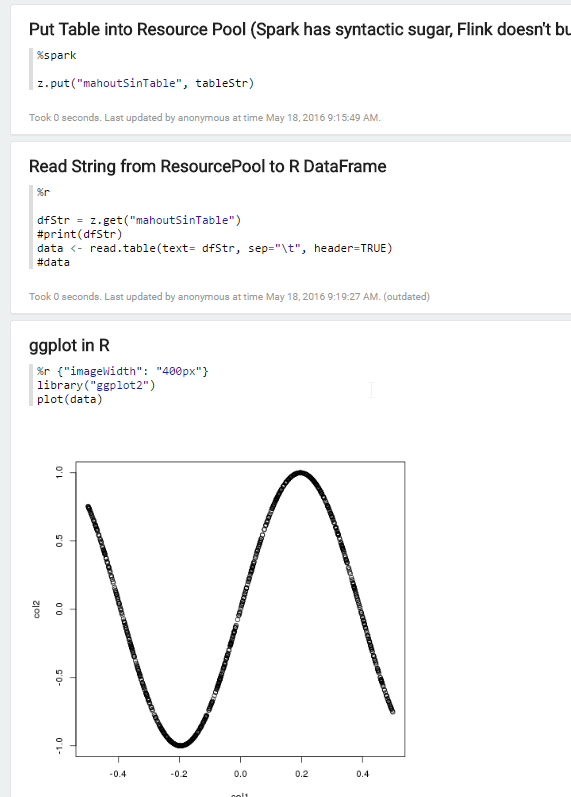
A post thought
Another way to skin this cat would be to simply convert the Mahout Matrix to an RDD and then register it as a DataFrame in Spark. That is correct, however the point of Mahout is to be engine agnostic, and as Flink is mainly focused on streaming data and not building out Python and R extensions, it is unlikely a similar functionality would be exposed there.
However, you’re through the looking-glass now, and if doing the distributed row matrix -> resilient distributed data set -> Spark data frame -> read in R makes more sense to you/your use case, go nuts. Write a blog of your own and link back to me 😉

Very nice. This is going to be very important as we make the integration a little more turnkey.
Not sure exporting a potentially huge DRM to an R dataframe will work, we’ll need some reduction but would want that to plot anyway. Now for some Mahout syntactic sugar to make it all easy.
BTW Mahout 0.12.1 is now released so no need for the snapshot build.
LikeLiked by 1 person
Great!
(1) I tend to do dialect imports in more succinct way these days (of course one can skip the comments):
import org.apache.mahout.math._
// Distributed matirx dialect
import drm._, RLikeDrmOps._
// in-memory dialects:
import sparkbindings._, RLikeOps._
// If needed, spark-specific, but i suspect it is not needed really if context is explicitly set up by would- be mahout zeppelin interpreter.:
import org.apache.mahout.sparkbindings._
(2) not sure what is the point of supporting distributed anything. It is distributed presumably because it is hard to keep it in memory. Therefore, plotting anything distributed potentially presents 2 problems: storage space and overplotting due to number of points. The idea is that we have to work out algorithms that condense big data information into small plottable information (like density grids, for example, or histograms).
on the other hand, if number of points is not actually a problem, then mahout can collect to in-memory matrix as easily as any of the following (implicit conversion implies collection
val mxA: Matrix = drmA
or
val mxA = drmA collect
or
val mxA = drmA:Matrix
any of those would do the same .
-d
LikeLiked by 1 person