We’re finishing up our series of blogs on providers with YouTube. After this we’ll get down business on building our own social monitoring quasi-app!
Getting YouTube Credentials
Before accessing any API, we of course need to get our credentials.
A good first step in an enterprise like this would be to read the docs, or at least thumb through them, regarding registering an application with the YouTube API.
But if you wanted to read lengthy docs, you probably wouldn’t be checking out this blog- so here’s the short version:
Open the Google Developers Dashboard we’re going to “Create a Project”
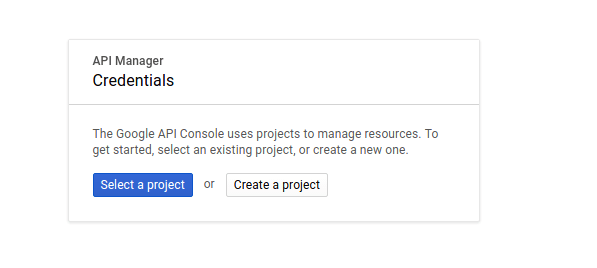
I’m going to call my application “Apache Streams Demo”
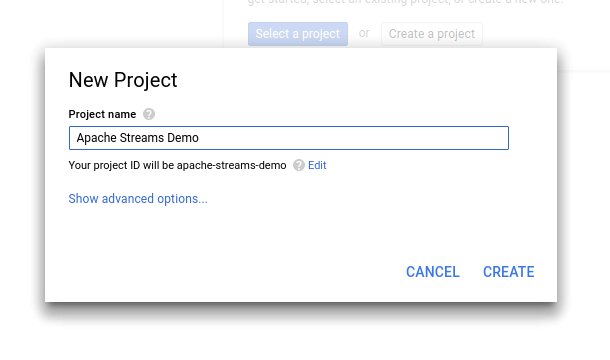
The next dialog is where things can go awry. First, right click “Enable APIs you plan to use” and open that link in a new tab, then click the drop down arrow next to “Create Credentials” and then select “Create Service Account Key” (we’ll come back to API enablement in a minute).
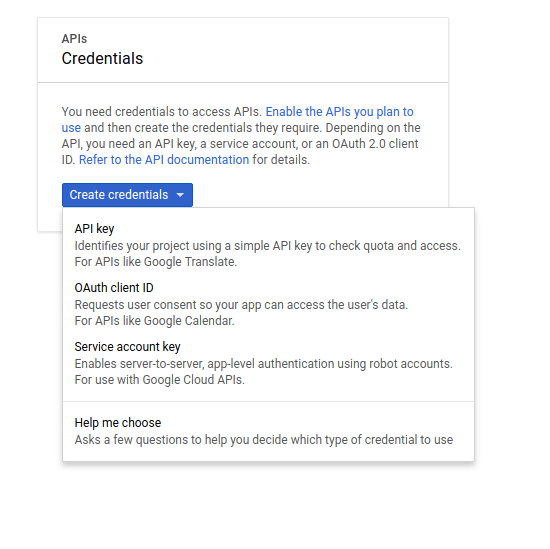
In the next screen choose ‘New Service Account’ and select P12 download type (not JSON which is the default). A dialogue will pop up with some key information. I set permissions to owner, but that probably isn’t necessary. After you hit create the key will be generated and downloaded.
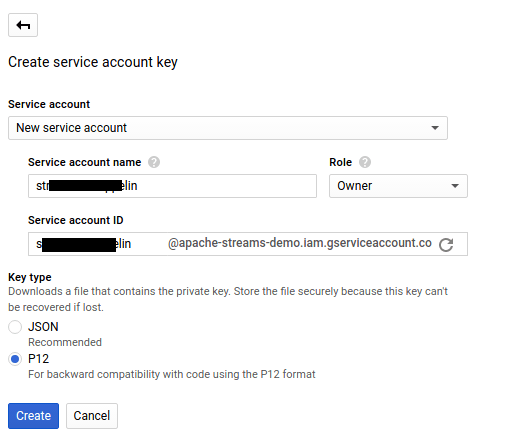
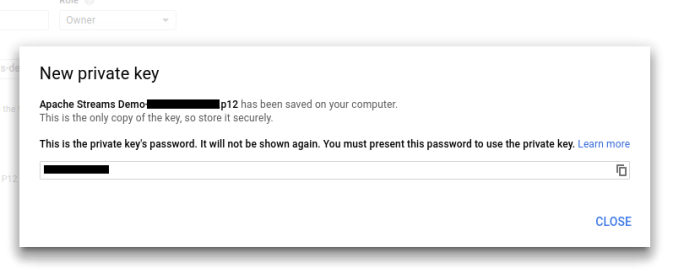
Set that .p12 file aside somewhere safe. We’ll need it soon.
Finally, we need to enable the services we want with this key. Go to the library tab (or open the ‘new tab’ you opened when you were creating the service account.
You’ll see a long list of all the APIs you can grant access to. We want to focus, for the moment on the YouTube services.
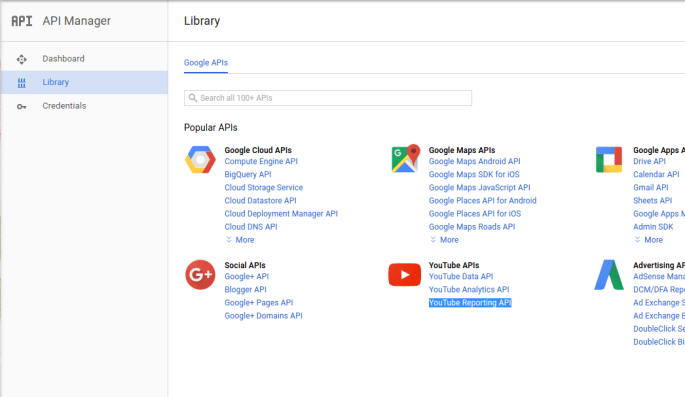
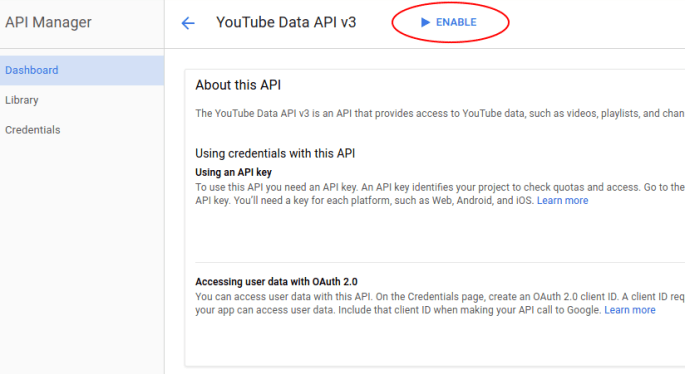
Go through each API you want (the YouTubes for this demo) and click “Enable” at the top.
Configurations
Full Credit to Steve Blockmon on this well done notebook.
Import Setup.json
Import YouTube.json
Setup.json
Steve and I are working toward a suite of notebooks aimed at creating a Social Monitoring Quasi-App. In the first paragraph of setup.json we see the following paragraph.
%spark.dep
z.reset()
z.addRepo("apache-snapshots").url("https://repository.apache.org/content/repositories/snapshots").snapshot()
z.load("org.apache.streams:streams-core:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-converters:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-pojo:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-provider-twitter:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-provider-facebook:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:streams-provider-youtube:0.5-incubating-SNAPSHOT")
z.load("org.apache.streams:google-gplus:0.5-incubating-SNAPSHOT")
We’re using the Zeppelin Dependency Loader here (you’ll likely see a message how this is deprecated). At the time of writing, there seems to be an issue with adding repositories via the GUI (e.g. it doesn’t pick up the new repository URL).
z.addRepo(... does add the new repository- in this case the Apache SNAPSHOT repository. The remaining lines load various Apache Streams providers.
In the next paragraph of the notebook Steve defines a couple of UDFs for dealing with punctuation and spaces in tweets and descriptions. These will come in handy later and are worth taking a moment to briefly grok.
Youtube.json
The first paragraph isn’t too exciting- some simple imports:
%spark import org.apache.streams.config._ import org.apache.streams.core._ import org.apache.youtube.pojo._ import com.typesafe.config._ import com.youtube.provider._ import java.util.Iterator
The second paragraph is where things start to get interesting. As we do, we are building a hocon configuration. We are also leveraging Zeppelin Dynamic Forms
val apiKey = z.input("apiKey", "")
val serviceAccountEmailAddress = z.input("serviceAccountEmailAddress", "")
val pathToP12KeyFile = z.input("pathToP12KeyFile", "")
val credentials_hocon = s"""
youtube {
apiKey = $apiKey
oauth {
serviceAccountEmailAddress = "$serviceAccountEmailAddress"
pathToP12KeyFile = "$pathToP12KeyFile"
}
}
"""
This paragraph will yield:

To find your API Key and Service account (assuming you didn’t write them down earlier- tsk tsk). Go back to your Google Developers Console, on the Credentials Tab, and click “manage service accounts” on the right. On this page you will see your service account and API Key. If you have multiple- make sure to use the one that cooresponds to the .p12 file you downloaded.

After you enter your crendentials and path to .p12file- make sure to click the “Play” button again to re-run the paragraph and update with your credentials.
The next configuration specifies who we want to follow. It is a list of UserIDs.
%spark
val accounts_hocon = s"""
youtube.youtubeUsers = [
# Apache Software Foundation - Topic
{ userId = "UCegQNPmRCAJvCq6JfHUKZ9A"},
# Apache Software Foundation
{ userId = "TheApacheFoundation"},
# Apache Spark
{ userId = "TheApacheSpark" },
# Apache Spark - Topic
{ userId = "UCwhtqOdWyCuqOboj-E1bpFQ"},
# Apache Flink Berlin
{ userId = "UCY8_lgiZLZErZPF47a2hXMA"},
# Apache Syncope
{ userId = "UCkrSQVb5Qzb13crS1kCOiQQ"},
# Apache Accumulo
{ userId = "apacheaccumulo"},
# Apache Hive - Topic
{ userId = "UCIjbkZAX5VlvSKoSzNUHIoQ"},
# Apache HBase - Topic
{ userId = "UCcGNHRiO9bi6BeH5OdhY2Kw"},
# Apache Cassandra - Topic
{ userId = "UC6nsS04n_wBpCDXqSAkFM-w"},
# Apache Hadoop - Topic
{ userId = "UCgRu3LbCjczooTVI9VSvstg"},
# Apache Avro - Topic
{ userId = "UCzHCk8Gl5eP85xz0HwXjkzw"},
# Apache Maven - Topic
{ userId = "UCBS2s2cwx-MW9rVeKwee_VA"},
# Apache Oozie - Topic
{ userId = "UCRyBrviuu3qMNliolYXvC0g"},
]
"""
I would recommend you stick with this list if you don’t have any activity on YouTube, or you’re just getting started and want to make sure some data is coming in. But in the spirit of creating our own little social monitoring quasi-app, consider replacing the proceeding paragraph with this:
%spark
val myChannel = z.input("my YouTube Channel", "")
val myId = z.input("my ID", "")
val accounts_hocon = s"""
youtube.youtubeUsers = [
{ userId = "${myId}"},
{ userId = "${myChannel}"}
]
"""
Which is going to give you a dynamic form in which a user can insert their own YouTube channel Id.
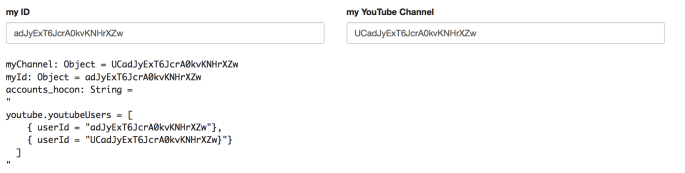
You’ll note here I have put in both my User ID and channel Id, and the only difference is adJyExT6JcrA0kvKNHrXZw vs UCadJyExT6JcrA0kvKNHrXZw is the proceeding UC in the latter- denoting it is a channel. Further if you notice the code- you submit User ID and channel ID as userId=.... This may be helpful because as we will see the channel and user APIs give us slightly different information.
To find channel IDs just surf around YouTube and go to channel pages. You’ll see the address is something like https://www.youtube.com/channel/UCGsMOj1pUwabpurXSKzfIfg (which is Astronomia Nova) and the UCGsMOj1pUwabpurXSKzfIfg part is the user ID.
Getting at that data
First we’re going to set up a ConfigFactory to load our config strings which we just did. This is going to create our YouTube configuration.
%spark val reference = ConfigFactory.load() val credentials = ConfigFactory.parseString(credentials_hocon) val accounts = ConfigFactory.parseString(accounts_hocon) val typesafe = accounts.withFallback(credentials).withFallback(reference).resolve() val youtubeConfiguration = new ComponentConfigurator(classOf[YoutubeConfiguration]).detectConfiguration(typesafe, "youtube");
Next we will pull information about the Channel(s) we noted in our accounts_hocon config string. This may be all of the Apache Accounts or our personal one. We will create an ArrayBuffer to store all of the responses we get. This should be old hat by now- you’ll notice the very similar API as accessing the Facebook and Twitter APIs from previous posts.
%spark
import com.typesafe.config._
import org.apache.streams.config._
import org.apache.streams.core._
import com.youtube.provider._
import org.apache.youtube.pojo._
import java.util.Iterator
val youtubeChannelProvider = new YoutubeChannelProvider(youtubeConfiguration);
youtubeChannelProvider.prepare(null)
youtubeChannelProvider.startStream()
val channel_buf = scala.collection.mutable.ArrayBuffer.empty[Object]
while( youtubeChannelProvider.isRunning()) {
val resultSet = youtubeChannelProvider.readCurrent()
resultSet.size()
val iterator = resultSet.iterator();
while(iterator.hasNext()) {
val datum = iterator.next();
channel_buf += datum.getDocument
}
}
channel_buf.size
The important thing to watch for, especially if using something other than the Apache userID set is that the output of the previous paragraph doesn’t end with something like: res45: Int = 0 because if that is the case- your buffer is empty and you will get errors when you try to make a table. If your buffer is empty, try using different user Ids.
Next we’ll get the user activity results.
%spark
val buf = scala.collection.mutable.ArrayBuffer.empty[Object]
val provider = new YoutubeUserActivityProvider(youtubeConfiguration);
provider.prepare(null)
provider.startStream()
while(provider.isRunning()) {
val resultSet = provider.readCurrent()
resultSet.size()
val iterator = resultSet.iterator();
while(iterator.hasNext()) {
val datum = iterator.next();
//println(datum.getDocument)
buf += datum.getDocument
}
}
buf.size
Basically the same idea here- same as last time, make sure that buffer is greater than 0!
Processing data into something we can play with
Our goal here is to get our data into a format we can play with. The easiest route to this end is to leverage Spark DataFrames / SQL Context and Zeppelin’s table display.
At the end of the last session on Apache Streams, we left as an exercise to the user a way to untangle all of the messy characters and line feeds. Now we provide the solution, a couple of User Defined Functions (UDFs) to strip all of that bad noise out.
%spark
import org.apache.spark.sql.functions._
import org.apache.spark.sql.UserDefinedFunction
import java.util.regex.Pattern
val toLowerCase = udf {
(text: String) => text.toLowerCase
}
val removeLineBreaks = udf {
(text: String) =>
val regex = "[\\n\\r]"
val pattern = Pattern.compile(regex)
val matcher = pattern.matcher(text)
// Remove all matches, split at whitespace (repeated whitespace is allowed) then join again.
val cleanedText = matcher.replaceAll(" ").split("[ ]+").mkString(" ")
cleanedText
}
val removePunctuationAndSpecialChar = udf {
(text: String) =>
val regex = "[\\.\\,\\:\\-\\!\\?\\n\\t,\\%\\#\\*\\|\\=\\(\\)\\\"\\>\\ posts(s)
val YoutubeTypeConverter = new YoutubeTypeConverter()
YoutubeTypeConverter.prepare()
val pages_datums = channel_buf.flatMap(x => YoutubeTypeConverter.process(new StreamsDatum(x)))
Now we create our DataFrame and register it as a temp table. Notice we use our “cleaner function” aka removePunctuationAndSpecialChar to clean column summary. This gives us a nice clean summary, while preserving the original actor.summary. If actor.summary doesn’t make any sense as a column name, see when we get to querying the table- it has to do with how spark queries the nested fields of a JSON.
%spark
import org.apache.streams.jackson.StreamsJacksonMapper;
import sqlContext._
import sqlContext.implicits._
val mapper = StreamsJacksonMapper.getInstance();
val pages_jsons = pages_datums.map(o => mapper.writeValueAsString(o.getDocument))
val pagesRDD = sc.parallelize(pages_jsons)
val pagesDF = sqlContext.read.json(pagesRDD)
val cleanDF = pagesDF.withColumn("summary", removePunctuationAndSpecialChar(pagesDF("actor.summary")))
cleanDF.registerTempTable("youtube_pages")
cleanDF.printSchema
In the line where we create page_json we do a map over the pages_datums we had created just previously (which was type scala.collection.mutable.ArrayBuffer[org.apache.streams.core.StreamsDatum] if you’re in to that sort of thing), changing each StreamsDatum into a JSON. We then paralellize that array, and do the standard Spark things to create a DataFrame from the RDD. Hocus-pocus and our channels have now been processed into a temp table called youtube_pages. The process is repeated for our users’ posts.
%spark import org.apache.streams.core.StreamsDatum import com.youtube.processor._ import scala.collection.JavaConversions._ //Normalize activities -> posts(s) val YoutubeTypeConverter = new YoutubeTypeConverter() YoutubeTypeConverter.prepare() val useractivity_posts = buf.flatMap(x => YoutubeTypeConverter.process(new StreamsDatum(x)))
And then…
%spark
import org.apache.streams.jackson.StreamsJacksonMapper;
import sqlContext._
import sqlContext.implicits._
val mapper = StreamsJacksonMapper.getInstance();
val jsons = useractivity_posts.map(o => mapper.writeValueAsString(o.getDocument))
val activitiesRDD = sc.parallelize(jsons)
val activitiesDF = sqlContext.read.json(activitiesRDD)
val cleanDF = activitiesDF.withColumn("content", removePunctuationAndSpecialChar(activitiesDF("content")))
cleanDF.registerTempTable("youtube_posts")
cleanDF.printSchema
Same idea, now we have a table called youtube_posts.
Let’s play.
At the end of the second paragraph for pages and posts above we called the .printSchema method on our DataFrame. This is helpful because it shows us … the schema of the DataFrame, which in a non-flat format such as JSON can be very useful. In general to traverse this schema we use field.subfield.subsubfield to query these things. Consider the following SQL statment:
%spark.sql select actor.id , actor.displayName , summary , actor.extensions.followers , actor.extensions.posts , extensions.youtube.statistics.viewCount from youtube_pages
and
%spark.sql select id , published , actor.id , actor.displayName , content , title from youtube_posts
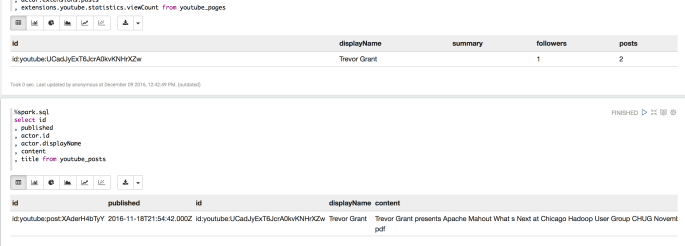
Here we see, I’m not such a popular guy on YouTube; 1 follower, 23 views, 1 post (a recent Apache Mahout Talk). My chance at being one of the great YouTube bloggers has passed me by, such is life.
Conclusions
The story arch of this series on Apache Streams has reached its zenith. If you have been following along, you’ll notice there isn’t really so much new information per Apache Streams anymore- the posts are more dedicated to ‘How to get your credentials for provider X’. I was thinking about doing one last one on Google+ since the credentialing is essentially the same, and you only need to change a couple of lines of code to say Google instead of YouTube.
In the dramatic conclusion to the Apache Streams mini-saga, we’re going to combine all of these together into a ‘quasi-app’ in which you collect all of your data from various providers and start merging it together using Spark SQL, visualizing with Angular, Zeppelin, and D3Js, and a little machine learning to see if we can’t learn a little something about our selves and the social world/bubble we (personally) live in.
