
It’s learning Friday, and I’m getting this out late so I’ll try to make it short and sweet. In this post we’re going to create a simple streaming program that hits the twitter statuses endpoint.
This is based on a demo from my recent talk at Flink Forward 2016. As always, I will be doing this in Apache Zeppelin notebooks, because I am lazy and don’t like to compile jars.
Step 1. Create API Keys
Go to twitter application management and create a new app. After you create the application, click on it. Under the Keys and Access Tokens Tab you will see the Consumer Key and Consumer Secret. Scroll down a little ways and you will also see Access Token and Access Token Secret. Leave this tab open, you’ll need it shortly.
Step 2. Open Zeppelin, create a new Interpreter for the Streaming Job.
In the first paragraph we are going to define our new interpreter. We need to add the dependency org.apache.flink:flink-connector-twitter_2.10:1.1.2. Also, if you’re running in a cluster you also need to download this jar to $FLINK_HOME/lib and restart the cluster.
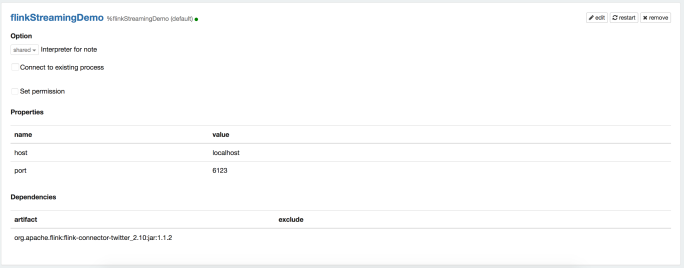
NOTE If you haven’t updated your Zeppelin in a while, you should do that. You need to have a version of Zeppelin that is using Apache Flink v1.1.2. This is important because that update to Zeppelin also introduced the Streaming context to Flink notebooks in Zeppelin. A quick way to test your if your Zeppelin is OK, is to run the following code in a paragraph, and see no errors.
%flink senv

Step 3. Set your authorization keys.
Refer to Step 1 for your specific keys, but create a notebook with the following code:
%flinkStreamingDemo ////////////////////////////////////////////////////// // Enter our Creds import java.util.Properties import org.apache.flink.streaming.connectors.twitter.TwitterSource val p = new Properties(); p.setProperty(TwitterSource.CONSUMER_KEY, ""); p.setProperty(TwitterSource.CONSUMER_SECRET, ""); p.setProperty(TwitterSource.TOKEN, ""); p.setProperty(TwitterSource.TOKEN_SECRET, "");
Obviously, plug your keys/tokens in- I’ve deleted mine.
Step 4. Create an end point to track terms
I’ve created a simple endpoint to capture all tweats containing the words pizza OR puggle OR poland. See the docs for more information on how twitter queries work.
%flinkStreamingDemo
import com.twitter.hbc.core.endpoint.{StatusesFilterEndpoint, StreamingEndpoint}
import scala.collection.JavaConverters._
// val chicago = new Location(new Location.Coordinate(-86.0, 41.0), new Location.Coordinate(-87.0, 42.0))
//////////////////////////////////////////////////////
// Create an Endpoint to Track our terms
class myFilterEndpoint extends TwitterSource.EndpointInitializer with Serializable {
@Override
def createEndpoint(): StreamingEndpoint = {
val endpoint = new StatusesFilterEndpoint()
//endpoint.locations(List(chicago).asJava)
endpoint.trackTerms(List("pizza", "puggle", "poland").asJava)
return endpoint
}
}
I’ve also commented out, but left as reference how you would do a location based filter.
Step 5. Set up the endpoints
Nothing exciting here, just setting up and initializing the endpoints.
%flinkStreamingDemo import org.apache.flink.streaming.api.scala.DataStream import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.core.fs.FileSystem.WriteMode val source = new TwitterSource(p) val epInit = new myFilterEndpoint() source.setCustomEndpointInitializer( epInit ) val streamSource = senv.addSource( source );
Step 6. Setup the Flink processing and windowing.
This is an embarrassingly simple example. Flink can do so much, but all we’re going to do is show off a little bit of its windowing capability (light years ahead of Apache spark streaming).
Everything else is somewhat trivial- this is the code of interest that the user is encouraged to play with.
%flinkStreamingDemo
streamSource.map(s => (0,1))
.keyBy(0)
// sliding time window of 1 minute length and 30 secs trigger interval
.timeWindow(Time.minutes(2), Time.seconds(30))
.sum(1)
.map(t => t._2)
.writeAsText("/tmp/2minCounts.txt", WriteMode.OVERWRITE)
senv.execute("Twitter Count")
We count the tweets in each window and the counts by window are saved to a text file. Not very exciting.
More information on windowing in Flink.
Exercises for the reader:
– Different windowing strategies
– Doing an action on the tweet like determining which keyword it contains
— Count by keyword
– Joining windows of different lengths (e.g. how many users tweeted in this window who have also tweeted in the current 24 hour window).
Etc.
Step 7. Visualize results.
Because there is a two minute window, you need to give this some time collect a window and write the results to 2minCounts.txt. So go grab a coffee, tweet how great this post is, etc.
When you come back, run the following code:
%flink import scala.io.Source val twoMinCnt = Source.fromFile("/tmp/2minCounts.txt").getLines.toList println("%table\ntime\tff_tweets\n" + twoMinCnt.zipWithIndex.map(o=> o._2+"\t"+o._1).mkString("\n"))
That code will read the text file and turn it in to a table that Zeppelin can understand and render in AngularJS. In this chart, the numbers on the x axis are the ‘epochs’ that is the 2 minute windows offset by 30 seconds each.

UPDATE
Remember how we created a new interpreter called %flinkStreamingDemo?
So here is the thing with a Flink streaming job, and Zeppelin. When you ‘execute’ the streaming paragraph from Step 6, that job is going to run forever.
If you are running Flink in a cluster, you have three options:
– Restart the interpreter. This will free the interpreter, but the streaming job will still be running- you can verify this in the Flink WebUI (also, the Flink WebUI is where you can stop the job). Now that control of the interpreter has been returned to you, you can run the visualization code with the %flinkStreamingDemo interpreter.
– You can use another Flink interpreter such as %flink. This will also work fine.
– You can use another Scala interpreter (such as the %ignite or %spark interpreter). This is fine, because the visualization code doesn’t leverage Flink in anyway, only pure Scala to read the file and convert it into a Zeppelin %table
If you’re in local mode (e.g. you don’t have a Flink Cluster running) you’ll likely see an error: java.net.BindException: Address already in use when you try to use another %flink interpreter. This is an opportunity for improvement in Zeppelin as the FlinkLocalMiniCluster always binds to 6123. In this case, the only option is #3 from above, simply run the code from any other Scala based interpreter (or use Python or R, but you’ll need to alter the code for those languages). All we need to do here is read the file, give it two headers and create a tab-separated string that starts with %table.
For example, this would work:
%spark import scala.io.Source val twoMinCnt = Source.fromFile("/tmp/2minCounts.txt").getLines.toList println("%table\ntime\tff_tweets\n" + twoMinCnt.zipWithIndex.map(o=> o._2+"\t"+o._1).mkString("\n"))
Again, because for the visualization, we don’t need anything that Flink does. We’re simply loading a file and creating a string.
Troubleshooting
If you see NO DATA AVAILABLE you either:
– didn’t wait long enough (wait at least the length of the window plus a little)
– you entered your credentials wrong
– you have a rarely use term and there is no data
Bad Auth
tail f*/log/*taskmanager*logprobably won’t work for you, but you need to check those logs for something that looks like this.
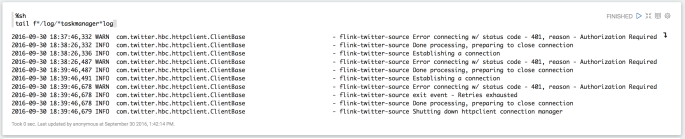
The whole enchilad
%flinkStreamingDemo
import java.util.Properties
import org.apache.flink.streaming.connectors.twitter.TwitterSource
import com.twitter.hbc.core.endpoint.{StatusesFilterEndpoint, StreamingEndpoint, Location}
import scala.collection.JavaConverters._
import org.apache.flink.streaming.api.scala.DataStream
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.core.fs.FileSystem.WriteMode
//////////////////////////////////////////////////////
// Enter our Creds
val p = new Properties();
p.setProperty(TwitterSource.CONSUMER_KEY, "");
p.setProperty(TwitterSource.CONSUMER_SECRET, "");
p.setProperty(TwitterSource.TOKEN, "");
p.setProperty(TwitterSource.TOKEN_SECRET, "");
val chicago = new Location(new Location.Coordinate(-86.0, 41.0), new Location.Coordinate(-87.0, 42.0))
//////////////////////////////////////////////////////
// Create an Endpoint to Track our terms
class myFilterEndpoint extends TwitterSource.EndpointInitializer with Serializable {
@Override
def createEndpoint(): StreamingEndpoint = {
val endpoint = new StatusesFilterEndpoint()
//endpoint.locations(List(chicago).asJava)
endpoint.trackTerms(List("pizza", "puggle", "poland").asJava)
return endpoint
}
}
val source = new TwitterSource(p)
val epInit = new myFilterEndpoint()
source.setCustomEndpointInitializer( epInit )
val streamSource = senv.addSource( source );
streamSource.map(s => (0,1))
.keyBy(0)
// sliding time window of 2 minute length and 30 secs trigger interval
.timeWindow(Time.minutes(2), Time.seconds(30))
.sum(1)
.map(t => t._2)
.writeAsText("/tmp/2minCounts.txt", WriteMode.OVERWRITE)
senv.execute("Twitter Count")

This almost works for me. I’m good up through step 6 — I have results accumulating in /tmp/2minCounts.txt — but I can’t figure out how to get anything visualized. The problem is that the cell with senv.execute continues to run indefinitely, so the cell with the angular code is stuck in “PENDING” mode and never runs.
LikeLike
David, thanks for the call out!
It makes me feel good to know people are actually using this. I see you found the answer, but I updated the post anyway.
I really appreciate the feedback.
LikeLike
I figured out my problem — I hadn’t realized I needed to use two different zeppelin interpreters.
LikeLike